- Data Hackers Newsletter
- Posts
- TurboQuant do Google reduz memória de IA em 6x (e pode cortar seus custos pela metade)
TurboQuant do Google reduz memória de IA em 6x (e pode cortar seus custos pela metade)
Entenda a inovação do Google que permite resumir absurdamente a memória demandada pela IA e assim reduzir seus custos
Data Hackers
16 de abril de 2026

Enquanto Large Language Models (LLMs) expandem suas janelas de contexto para processar documentos massivos e conversações complexas, eles enfrentam uma realidade brutal de hardware conhecida como "gargalo do cache Key-Value (KV)".
Cada palavra que um modelo processa precisa ser armazenada como um vetor de alta dimensionalidade na memória de alta velocidade. Para tarefas de longa duração, essa "cola digital" cresce rapidamente, devorando a memória de vídeo (VRAM) do sistema de unidades de processamento gráfico (GPU) usada durante a inferência, e desacelerando o desempenho do modelo drasticamente ao longo do tempo.
Mas não tema, o Google Research está aqui: ontem, a unidade dentro da gigante de buscas liberou seu pacote de algoritmos TurboQuant — uma inovação exclusivamente em software que fornece o blueprint matemático para compressão extrema de cache KV, possibilitando uma redução média de 6x na quantidade de memória KV que um determinado modelo usa, e aumento de desempenho de 8x no cálculo de logits de atenção, o que poderia reduzir custos para empresas que o implementarem em seus modelos em mais de 50%.
Os algoritmos teoricamente fundamentados e os papers de pesquisa associados estão disponíveis agora publicamente e de forma gratuita, incluindo para uso empresarial, oferecendo uma solução sem necessidade de treinamento para reduzir o tamanho do modelo sem sacrificar inteligência.
O gargalo de memória que está travando a evolução dos LLMs
Para entender por que o TurboQuant importa, é preciso primeiro compreender o "imposto de memória" da IA moderna. A quantização vetorial tradicional tem sido historicamente um processo "com vazamento".
Quando decimais de alta precisão são comprimidos em inteiros simples, o "erro de quantização" resultante se acumula, eventualmente fazendo com que os modelos alucinem ou percam coerência semântica.
Além disso, a maioria dos métodos existentes requer "constantes de quantização" — metadados armazenados junto aos bits comprimidos para informar ao modelo como descompactá-los. Em muitos casos, essas constantes adicionam tanto overhead — às vezes 1 a 2 bits por número — que negam completamente os ganhos da compressão.

Como funciona a arquitetura do TurboQuant
O TurboQuant resolve esse paradoxo através de um escudo matemático de duas etapas. O primeiro estágio utiliza o PolarQuant, que reimagina como mapeamos o espaço de alta dimensionalidade.
Em vez de usar coordenadas cartesianas padrão (X, Y, Z), o PolarQuant converte vetores em coordenadas polares consistindo de um raio e um conjunto de ângulos.
O breakthrough está na geometria: após uma rotação aleatória, a distribuição desses ângulos torna-se altamente previsível e concentrada. Como a "forma" dos dados agora é conhecida, o sistema não precisa mais armazenar constantes de normalização caras para cada bloco de dados. Ele simplesmente mapeia os dados em uma grade circular fixa, eliminando o overhead que os métodos tradicionais precisam carregar.
O segundo estágio atua como um verificador matemático de erros. Mesmo com a eficiência do PolarQuant, uma quantidade residual de erro permanece. O TurboQuant aplica uma transformação Quantized Johnson-Lindenstrauss (QJL) de 1 bit a esses dados restantes. Ao reduzir cada número de erro a um simples bit de sinal (+1 ou -1), o QJL serve como um estimador de viés zero. Isso garante que quando o modelo calcula um "score de atenção" — o processo vital de decidir quais palavras em um prompt são mais relevantes — a versão comprimida permanece estatisticamente idêntica ao original de alta precisão.
Benchmarks de desempenho: os números impressionam

O verdadeiro teste de qualquer algoritmo de compressão é o benchmark "Needle-in-a-Haystack", que avalia se uma IA pode encontrar uma única sentença específica escondida dentro de 100.000 palavras.
Em testes através de modelos open-source como Llama-3.1-8B e Mistral-7B, o TurboQuant alcançou pontuações perfeitas de recall, espelhando o desempenho de modelos não comprimidos enquanto reduzia o footprint de memória do cache KV por um fator de pelo menos 6x.
Essa "neutralidade de qualidade" é rara no mundo da quantização extrema, onde sistemas de 3 bits geralmente sofrem de degradação lógica significativa.
Resultados em diferentes aplicações
Aplicação | Melhoria de Desempenho | Redução de Memória |
|---|---|---|
Busca Semântica | Recall superior vs. RabbiQ e PQ | 6x em média |
Attention Logits (H100) | 8x mais rápido | 6x menos memória |
Needle-in-a-Haystack | 100% de recall | 5-6x de compressão |
Contextos longos (64K tokens) | Zero perda de acurácia | 5x de redução |
Além de chatbots, o TurboQuant é transformador para busca de alta dimensionalidade. Motores de busca modernos dependem cada vez mais de "busca semântica", comparando os significados de bilhões de vetores em vez de apenas combinar palavras-chave. O TurboQuant consistentemente alcança taxas de recall superiores comparado a métodos estado-da-arte existentes como RabbiQ e Product Quantization (PQ), tudo isso enquanto requer virtualmente zero tempo de indexação.
A reação da comunidade: validação na prática
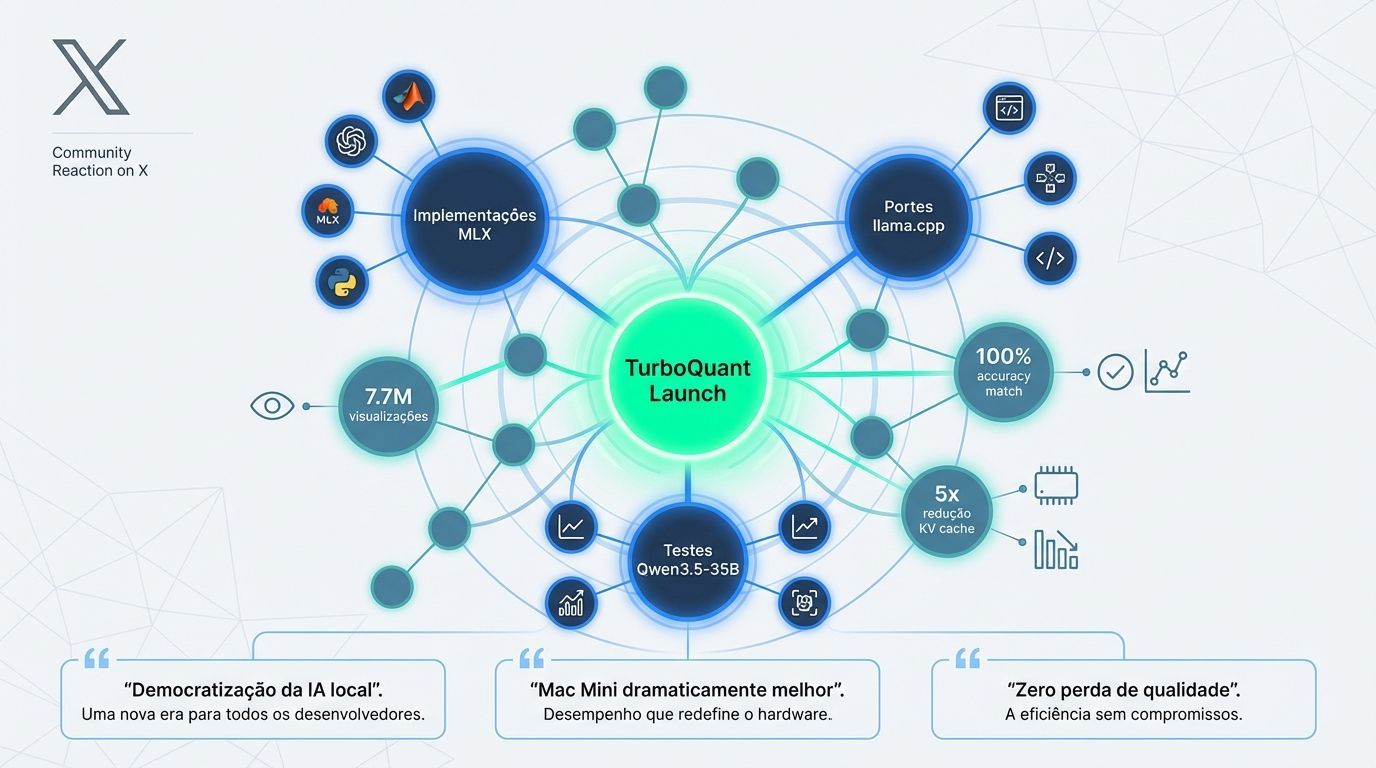
A reação no X, obtida via busca no Grok, incluiu uma mistura de admiração técnica e experimentação prática imediata. O anúncio original gerou engajamento massivo, com mais de 7,7 milhões de visualizações, sinalizando que a indústria estava faminta por uma solução para a crise de memória.
Dentro de 24 horas do lançamento, membros da comunidade começaram a portar o algoritmo para bibliotecas populares de IA local como MLX para Apple Silicon e llama.cpp.
Um dos benchmarks iniciais mais convincentes foi compartilhado por um analista técnico que implementou o TurboQuant em MLX para testar o modelo Qwen3.5-35B. Através de comprimentos de contexto variando de 8,5K a 64K tokens, ele reportou uma correspondência exata de 100% em cada nível de quantização, observando que o TurboQuant de 2,5 bits reduziu o cache KV em quase 5x com zero perda de acurácia.
Outros usuários focaram na democratização da IA de alto desempenho. Analistas argumentaram que o TurboQuant reduz significativamente a lacuna entre IA local gratuita e assinaturas caras de cloud. Eles notaram que modelos rodando localmente em hardware de consumidor como um Mac Mini "ficaram dramaticamente melhores", possibilitando conversas de 100.000 tokens sem a degradação típica de qualidade.
O impacto no mercado e no futuro do hardware
O lançamento do TurboQuant já começou a causar ondas através da economia tech mais ampla. Seguindo o anúncio, analistas observaram uma tendência de queda nos preços das ações de grandes fornecedores de memória, incluindo Micron e Western Digital.
A reação do mercado reflete uma percepção de que se gigantes de IA podem comprimir seus requisitos de memória por um fator de seis apenas através de software, a demanda insaciável por High Bandwidth Memory (HBM) pode ser temperada pela eficiência algorítmica.
À medida que avançamos mais fundo em 2026, a chegada do TurboQuant sugere que a próxima era de progresso em IA será definida tanto pela elegância matemática quanto pela força bruta. Ao redefinir eficiência através de compressão extrema, o Google está possibilitando "movimentação de memória mais inteligente" para agentes multi-etapas e pipelines densos de recuperação.
Considerações estratégicas para tomadores de decisão empresariais

Para empresas atualmente usando ou fazendo fine-tuning de seus próprios modelos de IA, o lançamento do TurboQuant oferece uma oportunidade rara de melhoria operacional imediata.
Diferentemente de muitos avanços em IA que requerem retreinamento custoso ou datasets especializados, o TurboQuant é livre de treinamento e agnóstico a dados.
Isso significa que organizações podem aplicar essas técnicas de quantização aos seus modelos fine-tuned existentes — sejam eles baseados em Llama, Mistral ou o próprio Gemma do Google — para realizar economias de memória e acelerações imediatas sem arriscar o desempenho especializado que trabalharam para construir.
Passos práticos para implementação
De um ponto de vista prático, equipes de TI e DevOps empresariais devem considerar os seguintes passos para integrar esta pesquisa em suas operações:
1. Otimizar Pipelines de Inferência
Integrar o TurboQuant em servidores de inferência de produção pode reduzir o número de GPUs necessárias para servir aplicações de contexto longo, potencialmente cortando custos de computação em cloud em 50% ou mais.
2. Expandir Capacidades de Contexto
Empresas trabalhando com documentação interna massiva podem agora oferecer janelas de contexto muito mais longas para tarefas de Retrieval-Augmented Generation (RAG) sem o overhead massivo de VRAM que anteriormente tornava tais recursos proibitivamente caros.
3. Aprimorar Deployments Locais
Para organizações com requisitos rigorosos de privacidade de dados, o TurboQuant torna viável rodar modelos altamente capazes e de grande escala em hardware on-premise ou dispositivos edge que eram anteriormente insuficientes para pesos de modelos de 32 bits ou até 8 bits.
4. Reavaliar Aquisição de Hardware
Antes de investir em clusters massivos de GPU com muito HBM, líderes de operações devem avaliar quanto de seu gargalo pode ser resolvido através desses ganhos de eficiência orientados por software.
FAQ: perguntas frequentes sobre o TurboQuant
O TurboQuant requer retreinamento dos modelos?
Não. Uma das maiores vantagens do TurboQuant é que ele é completamente livre de treinamento e pode ser aplicado a modelos existentes sem modificação.
Qual é a redução de custo esperada?
Empresas podem esperar redução de custos de mais de 50% em infraestrutura de GPU, dependendo de seus casos de uso específicos e configurações de hardware.
O TurboQuant funciona com qualquer modelo?
Sim, o algoritmo é agnóstico ao modelo e foi testado com sucesso em Llama, Mistral, Gemma e outros modelos populares.
Há perda de qualidade na compressão?
Os testes demonstram zero perda de qualidade em benchmarks padrão como Needle-in-a-Haystack, com 100% de recall mantido.
Quando o TurboQuant estará disponível?
Os algoritmos e papers de pesquisa já estão disponíveis publicamente e gratuitamente, incluindo para uso comercial.
Conclusão: a era da eficiência algorítmica
Ultimamente, o TurboQuant prova que o limite da IA não é apenas quantos transistores podemos comprimir em um chip, mas quão elegantemente podemos traduzir a complexidade infinita da informação no espaço finito de um bit digital.
Para as empresas, isso é mais do que apenas um paper de pesquisa; é um desbloqueio tático que transforma hardware existente em um ativo significativamente mais poderoso. A indústria está mudando de um foco em "modelos maiores" para "memória melhor", uma mudança que poderia reduzir globalmente os custos de servir IA.
A chegada do TurboQuant marca um momento crucial na evolução da infraestrutura de IA: a descoberta de que a eficiência matemática pode ser tão transformadora quanto o poder de processamento bruto. Para aqueles que acompanham de perto o desenvolvimento de IA, este é um lembrete de que os maiores avanços muitas vezes vêm não de hardware mais poderoso, mas de software mais inteligente.