- Data Hackers Newsletter
- Posts
- RAG: O que são Embeddings e como funcionam
RAG: O que são Embeddings e como funcionam
Entenda como os embeddings ajudam o sistema a encontrar e recuperar as informações mais adequadas para você
Data Hackers
20 de fevereiro de 2026
Quando falamos sobre sistemas de Retrieval Augmented Generation (RAG) com Large Language Models (LLMs), um dos conceitos fundamentais que precisamos entender são os embeddings. Mas o que exatamente são embeddings e por que eles são tão importantes para o funcionamento eficaz de sistemas RAG?
Neste artigo, vamos explorar em detalhes o papel dos embeddings em sistemas RAG, como eles funcionam e por que são superiores às buscas tradicionais baseadas em texto.
Entendendo RAG e o papel dos embeddings
Imagine que você está procurando documentos em uma vasta biblioteca digital. Você busca informações sobre um tópico específico. Em sistemas RAG com LLMs, o sistema faz muito mais do que simplesmente procurar texto que corresponda à sua consulta.
O sistema realmente mergulha no contexto mais profundo dos documentos e encontra as informações mais relevantes para o seu tópico. É aqui que os embeddings entram em cena. Eles ajudam o sistema a entender e recuperar as informações mais adequadas para você.
Por que embeddings ao invés de busca tradicional de texto?
Uma busca tradicional de texto, como a realizada pelo Solr, opera em correspondências literais de texto. É eficiente, mas pode perder documentos nuançados ou contextualmente relevantes que não contenham os termos de busca exatos.
Os embeddings, por outro lado, representam documentos como vetores em um espaço de alta dimensão, capturando relações semânticas além da mera presença de palavras.
No contexto de um grande corpus, o desafio é identificar o conjunto mais amplo de chunks de documentos relevantes dentro da janela de contexto finita de um LLM. Os embeddings se destacam aqui, permitindo que o sistema identifique e recupere conteúdo que uma busca literal de texto poderia ignorar.

Tipos de embeddings e algoritmos de chunking em RAG LLMs
Tipos de embeddings
No contexto de RAG LLMs, vários tipos de embeddings podem ser utilizados, como:
Word2Vec: Captura relações semânticas baseadas em co-ocorrências de palavras
GloVe: Similar ao Word2Vec, mas com abordagem diferente para capturar contexto global
BERT embeddings: Derivados de modelos transformer, são contextualmente mais ricos, capturando as nuances dos significados das palavras com base no texto circundante
Cada um desses tipos tem características únicas que podem ser mais adequadas dependendo do caso de uso específico.
Algoritmos de chunking
O processo de dividir documentos em chunks semanticamente coesos é fundamental em RAG LLMs. Algoritmos como Sentence-BERT podem ser usados para gerar embeddings para sentenças individuais, facilitando a identificação de chunks semanticamente densos.
A escolha do algoritmo influencia significativamente a granularidade e relevância das informações recuperadas.
Chunking em bancos de dados vetoriais vs. busca regular
O processo de chunking em bancos de dados vetoriais envolve segmentar documentos em porções semanticamente coesas, garantindo que cada chunk encapsule uma ideia ou conceito completo. Isso é diferente da busca tradicional de texto, onde o foco está mais em palavras-chave e fragmentos específicos de texto.

Integrando embeddings com LLMs
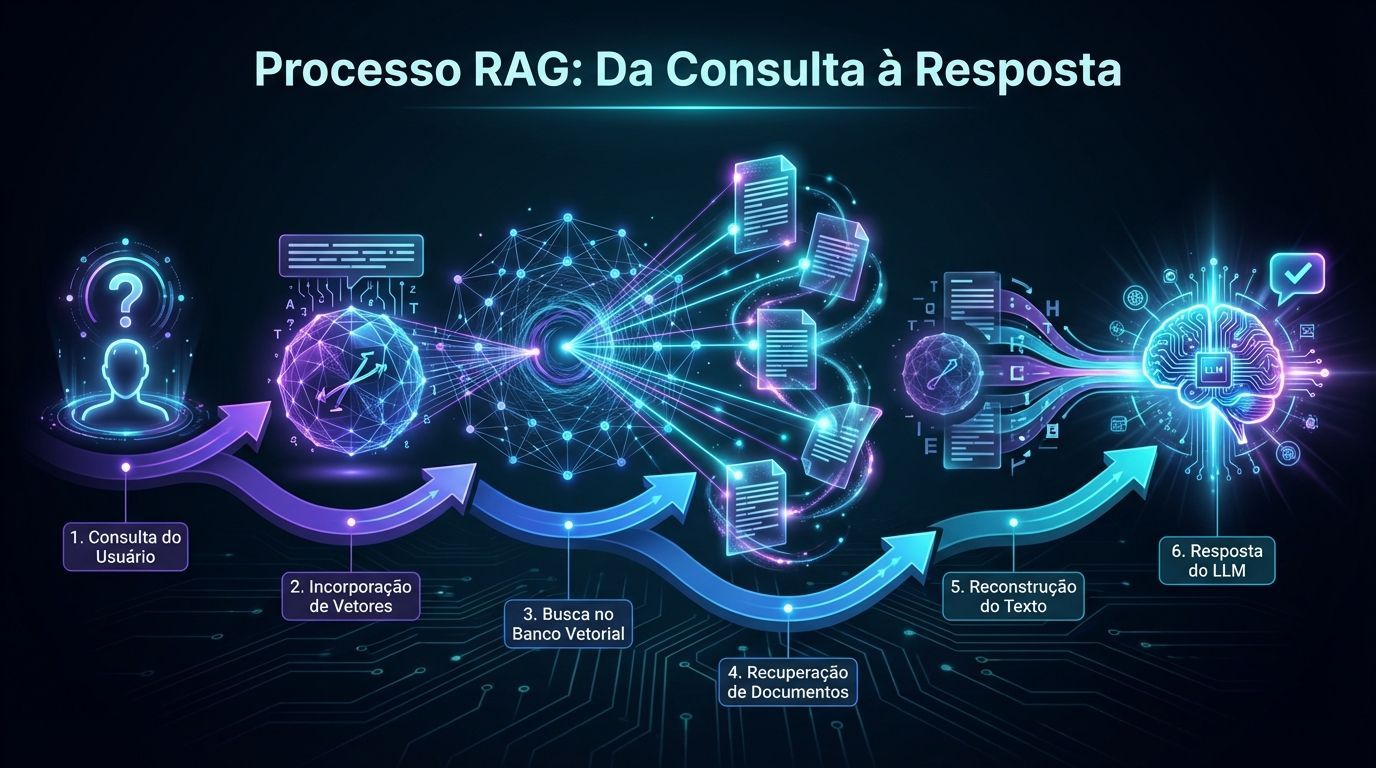
É um equívoco comum pensar que os embeddings são alimentados diretamente nos LLMs como parte do prompt. Na realidade, os embeddings servem como uma etapa intermediária. Eles orientam a recuperação de chunks de texto do banco de dados, que são então convertidos de volta para um formato legível e combinados com o prompt original do usuário.
Como funciona o processo:
O usuário faz uma consulta
A consulta é convertida em embedding
O sistema busca os chunks mais relevantes no banco de dados vetorial
Os chunks recuperados são convertidos de volta para texto
O texto recuperado é combinado com o prompt original
Este prompt enriquecido é alimentado ao LLM
O LLM não processa os embeddings diretamente. Em vez disso, ele trabalha com o texto enriquecido, aproveitando seus próprios mecanismos de codificação para interpretar essas informações.
Impacto do RAG na arquitetura de LLMs
Integrar RAG em um LLM não é apenas uma questão de envolver um modelo existente em uma nova camada. Em sistemas RAG que usam GPT-4 como modelo LLM, a arquitetura do próprio LLM não é modificada.
Em vez disso, uma camada vetorial é adicionada na frente, aumentando os prompts. Isso permite que o modelo lide efetivamente com prompts enriquecidos, interpretando o contexto adicional e integrando-o perfeitamente com a consulta original do usuário.
Os desafios de implementar RAG
Sistemas RAG são inerentemente complexos devido a vários fatores:
Desafio | Descrição |
|---|---|
Limitações da janela de contexto | O desafio é encontrar as informações mais relevantes dentro das restrições da janela de contexto do LLM |
Busca por relevância | Identificar os chunks de documentos mais pertinentes é uma tarefa nuançada, envolvendo mais do que apenas encontrar correspondências literais de texto |
Estratégias de chunking | Diferentes abordagens para dividir documentos em chunks gerenciáveis podem impactar a precisão e relevância dos resultados de busca |
Melhores práticas para trabalhar com embeddings em RAG
Para obter os melhores resultados ao implementar sistemas RAG, considere:
Escolha do modelo de embedding: Selecione um modelo que melhor se adapte ao seu domínio específico
Tamanho do chunk: Experimente diferentes tamanhos de chunk para encontrar o equilíbrio ideal entre contexto e precisão
Sobreposição de chunks: Considere sobrepor chunks para evitar perda de contexto nas bordas
Atualização regular: Mantenha seus embeddings atualizados conforme novos documentos são adicionados
Otimização de consultas: Ajuste como as consultas são convertidas em embeddings para melhorar a recuperação
FAQ sobre embeddings em RAG
P: Embeddings são sempre necessários em sistemas RAG?
R: Sim, embeddings são fundamentais para sistemas RAG modernos, pois permitem busca semântica em vez de apenas correspondência literal de palavras.
P: Qual a diferença entre embeddings e tokenização?
R: Tokenização divide texto em unidades menores (tokens), enquanto embeddings convertem essas unidades em representações numéricas densas que capturam significado semântico.
P: Posso usar diferentes modelos de embedding para consultas e documentos?
R: Tecnicamente é possível, mas não é recomendado. Usar o mesmo modelo garante que consultas e documentos sejam representados no mesmo espaço vetorial.
P: Como escolher entre Word2Vec, GloVe e BERT?
R: BERT geralmente oferece melhor desempenho para tarefas de compreensão de linguagem natural, mas pode ser mais lento. Word2Vec e GloVe são mais rápidos mas menos contextuais.
Conclusão
Em resumo, os embeddings desempenham um papel crucial em RAG LLMs, permitindo uma recuperação de informações mais nuançada e contextualmente rica. A integração de embeddings em LLMs não é apenas uma questão de compressão ou pular etapas no processamento; trata-se de melhorar a capacidade do modelo de compreender e responder a consultas complexas.
Implementar RAG envolve ajustes arquitetônicos no LLM e uma compreensão profunda dos desafios associados à busca por relevância, limitações da janela de contexto e estratégias eficazes de chunking.
À medida que a tecnologia de IA continua evoluindo, entender e dominar o uso de embeddings em sistemas RAG se tornará cada vez mais importante para construir aplicações de IA mais inteligentes e eficientes.