- Data Hackers Newsletter
- Posts
- RAG em produção: 9 arquiteturas essenciais que vão além do Naive RAG
RAG em produção: 9 arquiteturas essenciais que vão além do Naive RAG
Entenda as diferenças entre as arquiteturas de RAG e saiba como escolher a certa para cada situação
Data Hackers
16 de abril de 2026
Seu chatbot acabou de informar a um cliente que sua política de devolução é de 90 dias. Na verdade, são 30. Depois, ele descreve funcionalidades que seu produto nem sequer possui.
Essa é a diferença entre uma demo impressionante e um sistema de produção real. Modelos de linguagem soam confiantes mesmo quando estão errados, e em produção isso sai caro — muito caro.
É por isso que equipes sérias de AI usam RAG (Retrieval-Augmented Generation). Não porque está na moda, mas porque mantém os modelos ancorados em informações reais.
O que a maioria das pessoas não percebe é que não existe um único RAG. Existem múltiplas arquiteturas, cada uma resolvendo um problema diferente. Escolha a errada e você desperdiça meses.
Este guia apresenta as arquiteturas RAG que realmente funcionam em produção.
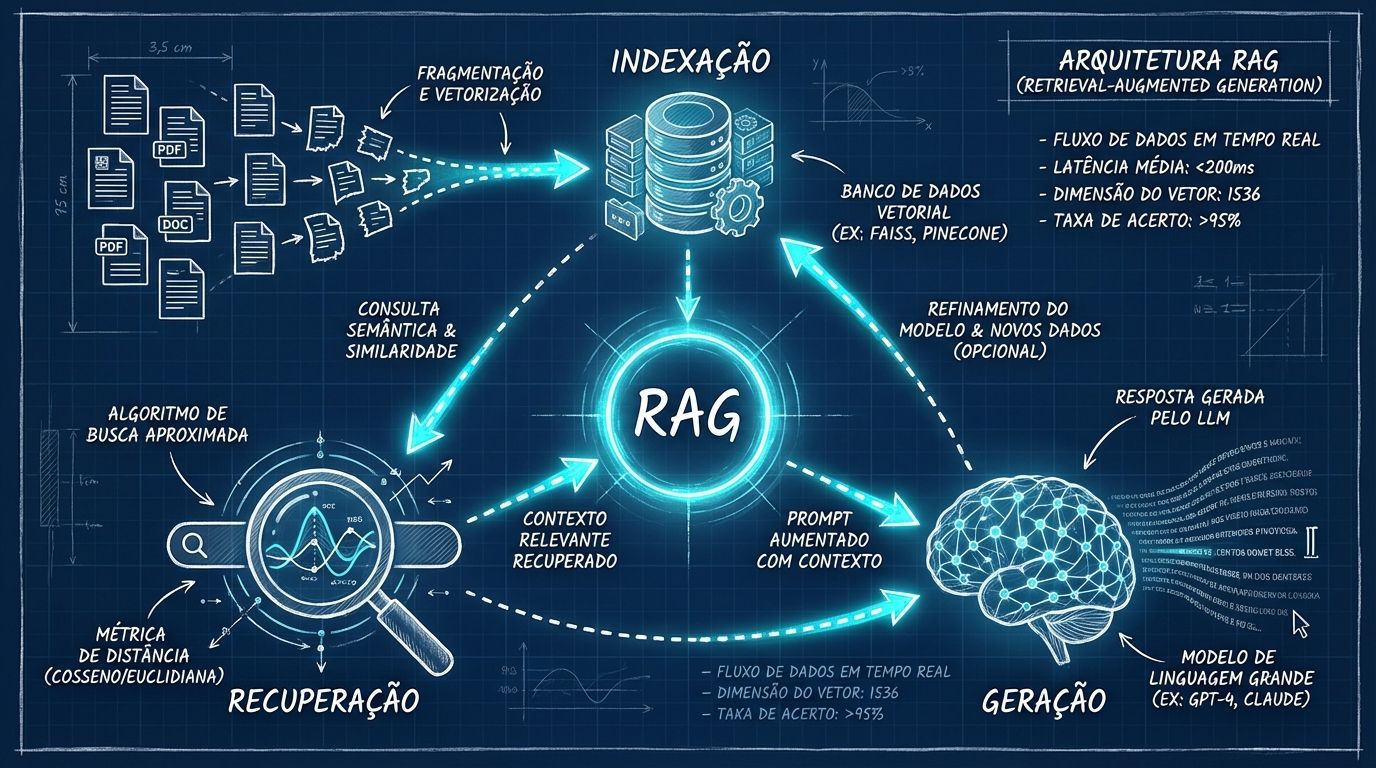
O que é RAG e por que ele realmente importa?
RAG (Retrieval-Augmented Generation) é uma técnica que combina a capacidade de geração de texto dos Large Language Models (LLMs) com a busca e recuperação de informações de fontes externas. Em vez de depender apenas do conhecimento embutido no modelo durante o treinamento, o RAG recupera informações relevantes de uma base de dados ou documentos antes de gerar uma resposta.
Por que isso importa?
Reduz alucinações: Modelos puros de linguagem frequentemente inventam informações. O RAG ancora as respostas em dados reais.
Conhecimento atualizado: Você não precisa retreinar o modelo toda vez que suas informações mudam. Basta atualizar sua base de conhecimento.
Transparência: É possível rastrear de onde vieram as informações da resposta, criando sistemas mais auditáveis.
Economia: Retreinar modelos é caro. Atualizar documentos não.
As 9 arquiteturas RAG que todo desenvolvedor precisa conhecer
1. Naive RAG: o ponto de partida (mas não o final)
A arquitetura Naive RAG é a forma mais básica e comum de implementação. O processo funciona assim:
Indexação: Seus documentos são divididos em chunks e armazenados em um banco vetorial
Recuperação: Quando uma query chega, o sistema busca os chunks mais similares semanticamente
Geração: O LLM recebe os chunks recuperados como contexto e gera a resposta
Quando usar:
Prototipagem rápida
Casos de uso simples com documentos homogêneos
Quando você está validando a viabilidade de uma solução RAG
Limitações:
Não lida bem com perguntas complexas ou multi-hop
Problemas com chunk size inadequado
Dificuldade em agregar informações de múltiplas fontes

2. Advanced RAG: otimizando a recuperação
O Advanced RAG adiciona camadas de pré-processamento e pós-processamento ao fluxo básico:
Pré-recuperação:
Query rewriting: reformula a pergunta do usuário para melhorar a busca
Query expansion: gera variações da pergunta original
Query decomposition: quebra perguntas complexas em sub-perguntas
Pós-recuperação:
Re-ranking: reordena os documentos recuperados usando modelos mais sofisticados
Context compression: remove informações irrelevantes dos documentos recuperados
Filtering: aplica filtros baseados em metadados ou relevância
Quando usar:
Quando o Naive RAG retorna muitos falsos positivos
Para melhorar a precisão em domínios específicos
Quando você precisa balancear relevância e diversidade de resultados
3. Modular RAG: arquitetura para sistemas escaláveis
O Modular RAG trata cada componente do pipeline como um módulo independente que pode ser configurado, testado e otimizado separadamente.
Componentes principais:
Módulo | Função | Exemplos |
|---|---|---|
Retriever | Busca documentos | Dense retrieval, BM25, hybrid search |
Reranker | Reordena resultados | Cross-encoder models, LLM-based ranking |
Generator | Produz resposta | GPT-4, Claude, Llama |
Router | Direciona queries | Rule-based, ML-based routing |
Vantagens:
Facilita experimentação com diferentes componentes
Permite otimização independente de cada módulo
Simplifica manutenção e debugging

4. Agentic RAG: inteligência autônoma
Nesta arquitetura, um agente AI decide dinamicamente como recuperar e processar informações:
Capacidades do agente:
Planejar estratégias de busca complexas
Decidir quando fazer novas buscas
Avaliar se as informações recuperadas são suficientes
Chamar ferramentas externas quando necessário
Exemplo de fluxo:
Usuário pergunta: "Qual foi a performance financeira da empresa nos últimos 3 anos?"
Agente decompõe em: buscar dados de 2022, 2023 e 2024
Agente recupera documentos financeiros de cada ano
Agente identifica que faltam dados de um trimestre
Agente busca especificamente esse trimestre
Agente agrega todas as informações e gera resposta
Quando usar:
Perguntas complexas que requerem múltiplas etapas
Cenários onde a estratégia de busca não é óbvia
Sistemas que precisam interagir com múltiplas fontes de dados
5. Self-RAG: auto-reflexão e correção
Self-RAG adiciona um mecanismo de auto-avaliação ao processo de geração:
Tokens de reflexão:
Retrieve: O modelo decide se precisa recuperar informações
ISREL: Avalia se o documento recuperado é relevante
ISSUP: Verifica se a resposta é suportada pelo documento
ISUSE: Determina se a resposta é útil
Fluxo de funcionamento:
Modelo gera token [Retrieve] se necessário
Sistema recupera documentos relevantes
Modelo avalia relevância com [ISREL]
Modelo gera resposta
Modelo verifica suporte factual com [ISSUP]
Modelo avalia utilidade com [ISUSE]
Esta arquitetura reduz significativamente alucinações ao adicionar checkpoints de qualidade.
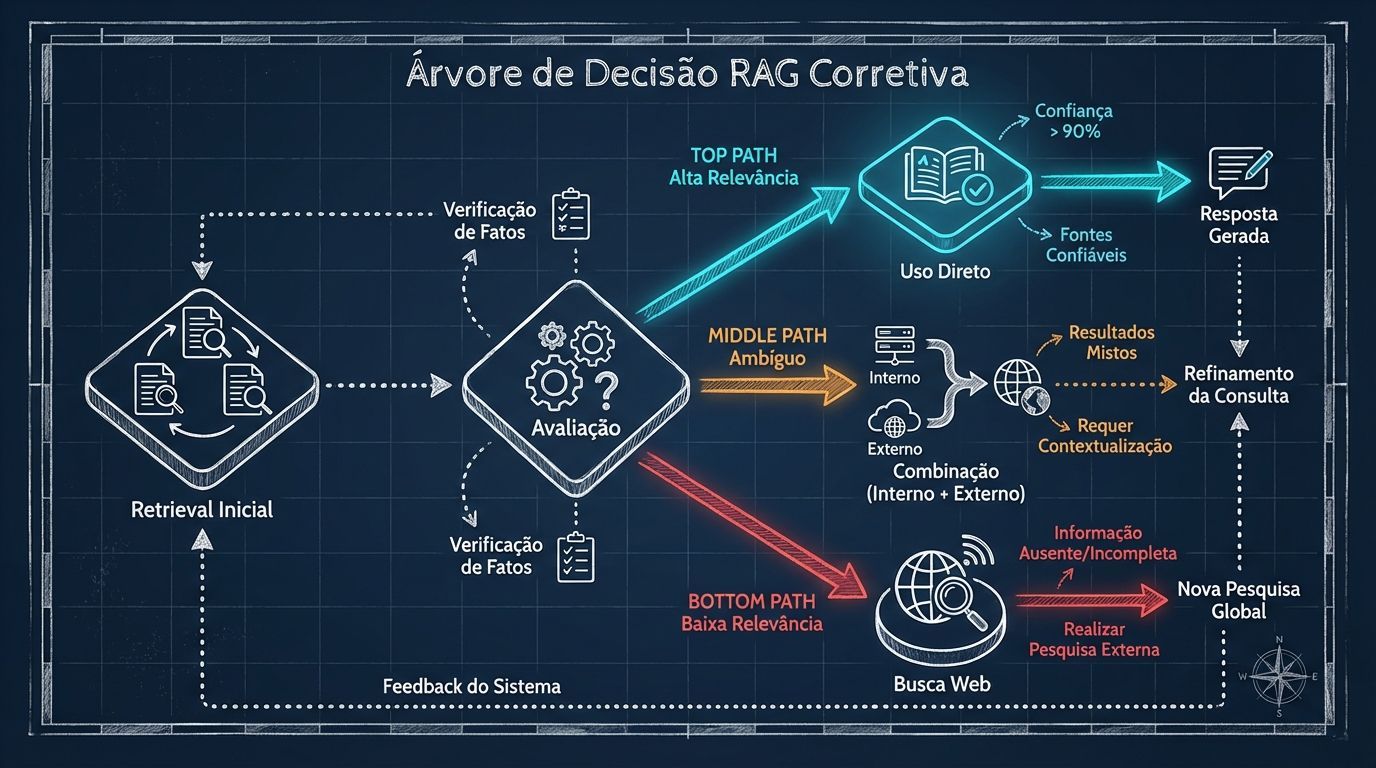
6. Corrective RAG (CRAG): corrigindo recuperações imperfeitas
CRAG assume que o retrieval pode estar errado e adiciona mecanismos de correção:
Pipeline de correção:
Retrieval inicial: Busca documentos como no RAG tradicional
Avaliação: Um avaliador (retrieval evaluator) classifica cada documento
Decisão adaptativa:
Se documentos são altamente relevantes → usa diretamente
Se relevância é baixa → busca na web
Se ambíguo → combina fontes internas e externas
Quando usar:
Domínios onde sua base de conhecimento pode estar incompleta
Cenários que exigem informações atualizadas
Quando a qualidade do retrieval é inconsistente
7. Adaptive RAG: escolhendo a estratégia certa dinamicamente
Adaptive RAG não usa uma única abordagem, mas seleciona a estratégia mais adequada para cada query:
Estratégias disponíveis:
Single-step: Para perguntas simples e diretas
Multi-step: Para perguntas que requerem múltiplas buscas
No retrieval: Quando o LLM já tem conhecimento suficiente
Web search: Para informações atualizadas
Classificador de queries:
O sistema usa um modelo classificador que analisa:
Complexidade da pergunta
Temporalidade (perguntas sobre eventos recentes)
Especificidade do domínio
Necessidade de múltiplas fontes
Exemplo prático:
"Qual a capital da França?" → No retrieval
"Quais são nossos produtos?" → Single-step RAG
"Compare o desempenho dos produtos X e Y nos últimos 2 anos" → Multi-step RAG
"Qual foi a última atualização do produto Z?" → Web search
8. Graph RAG: conectando informações através de grafos de conhecimento
Graph RAG vai além da similaridade vetorial e usa as relações estruturadas entre informações:
Componentes principais:
Knowledge Graph: Representa entidades e suas relações
Entity Extraction: Identifica entidades na query
Graph Traversal: Navega pelo grafo para encontrar informações relacionadas
Context Assembly: Combina informações do grafo com recuperação vetorial
Vantagens:
Captura relações complexas entre conceitos
Permite queries sobre relacionamentos
Facilita raciocínio multi-hop
Exemplo de aplicação:
Query: "Quem trabalhou com o CEO antes dele assumir a empresa?"
Extrai entidade: CEO atual
Busca no grafo: relação "trabalhou_com"
Filtra por período: antes da data de contratação
Agrega informações de perfis profissionais

9. Fusion RAG: combinando múltiplas estratégias de recuperação
Fusion RAG combina diferentes métodos de retrieval para obter melhores resultados:
Métodos combinados:
Dense retrieval: Embeddings semânticos (ex: BERT, Sentence Transformers)
Sparse retrieval: Busca por palavras-chave (BM25, TF-IDF)
Hybrid search: Combina dense e sparse
Cross-encoder reranking: Avaliação profunda de relevância
Estratégias de fusão:
Reciprocal Rank Fusion (RRF): Combina rankings de diferentes métodos
Weighted fusion: Atribui pesos a diferentes retrievers
Cascade fusion: Usa métodos em sequência
Quando usar:
Quando nenhum método de retrieval único é suficiente
Para maximizar recall e precision simultaneamente
Em domínios com terminologia técnica e conceitos abstratos
Como escolher a arquitetura RAG certa para seu projeto
Não existe uma arquitetura RAG "melhor". A escolha depende de:
1. Complexidade das queries:
Perguntas simples → Naive RAG ou Advanced RAG
Perguntas complexas → Agentic RAG ou Adaptive RAG
Perguntas sobre relacionamentos → Graph RAG
2. Qualidade da base de conhecimento:
Base completa e confiável → Advanced RAG
Base incompleta → Corrective RAG
Base estruturada → Graph RAG
3. Requisitos de precisão:
Alta precisão crítica → Self-RAG ou Corrective RAG
Balanceamento precision/recall → Fusion RAG
4. Recursos computacionais:
Recursos limitados → Naive RAG ou Advanced RAG
Recursos abundantes → Agentic RAG ou Graph RAG
5. Necessidade de transparência:
Alta auditabilidade → Graph RAG ou Modular RAG
Menor necessidade → Qualquer arquitetura
Implementando RAG em produção: checklist essencial
[ ] Defina métricas claras de sucesso (accuracy, latência, custo)
[ ] Estabeleça um processo de avaliação contínua
[ ] Implemente logging detalhado de queries e respostas
[ ] Configure monitoramento de qualidade em tempo real
[ ] Crie um pipeline de feedback de usuários
[ ] Implemente versionamento de documentos e modelos
[ ] Estabeleça processos de atualização da base de conhecimento
[ ] Configure fallbacks para casos de falha
[ ] Implemente rate limiting e controle de custos
[ ] Documente decisões arquiteturais e trade-offs
Armadilhas comuns ao implementar RAG
1. Chunk size inadequado:
Chunks muito pequenos perdem contexto
Chunks muito grandes diluem relevância
Solução: Experimente diferentes tamanhos e use overlap
2. Ignorar qualidade dos embeddings:
Embeddings genéricos podem falhar em domínios específicos
Solução: Fine-tune embeddings ou use modelos especializados
3. Não validar qualidade do retrieval:
Assumir que o retrieval está funcionando bem
Solução: Meça precision@k e recall@k regularmente
4. Falta de metadata:
Não usar informações estruturadas disponíveis
Solução: Implemente filtros por metadata (data, tipo, fonte)
5. Não considerar custo:
RAG pode ficar caro em escala
Solução: Use caching, otimize número de chunks recuperados
O futuro das arquiteturas RAG
As arquiteturas RAG estão evoluindo rapidamente:
1. RAG multimodal: Recuperação de imagens, áudios e vídeos, não apenas texto
2. RAG colaborativo: Múltiplos agentes trabalhando juntos para responder queries complexas
3. RAG com memory: Sistemas que aprendem com interações anteriores
4. RAG federado: Busca em múltiplas bases de conhecimento distribuídas
5. RAG explicável: Sistemas que explicam por que recuperaram determinados documentos
Conclusão: além do hype, foque na execução
RAG transformou a forma como construímos aplicações de AI confiáveis. Mas a tecnologia sozinha não garante sucesso.
O que realmente importa:
Escolher a arquitetura certa para seu problema específico
Investir em qualidade da base de conhecimento
Implementar avaliação contínua
Iterar baseado em feedback real de usuários
Comece com Naive RAG para validar a ideia. Quando entender os pontos fracos, evolua para arquiteturas mais sofisticadas.
E lembre-se: a melhor arquitetura RAG é aquela que resolve o problema do seu usuário com o menor custo e complexidade possível.
Agora é sua vez de construir sistemas RAG que realmente funcionam em produção. Comece simples, meça tudo, e evolua baseado em dados reais.
Perguntas frequentes sobre RAG
Q: RAG substitui o fine-tuning de modelos?
A: Não necessariamente. RAG é ótimo para conhecimento factual que muda frequentemente. Fine-tuning é melhor para adaptar o estilo de escrita ou comportamento do modelo. Muitas vezes, a melhor solução combina ambos.
Q: Qual o tamanho ideal de chunk para documentos?
A: Não existe tamanho universal. Para textos técnicos, 256-512 tokens funciona bem. Para documentos narrativos, 512-1024 tokens. O importante é experimentar e medir o impacto na qualidade das respostas.
Q: Como lidar com documentos em múltiplos idiomas?
A: Use embeddings multilíngues (como multilingual-E5) ou mantenha bases separadas por idioma. A segunda opção geralmente oferece melhor qualidade.
Q: RAG funciona bem para dados estruturados (tabelas, planilhas)?
A: Sim, mas requer tratamento especial. Converta tabelas em texto descritivo ou use Graph RAG para manter relações estruturadas.
Q: Como garantir que RAG não retorne informações sensíveis?
A: Implemente controles de acesso no nível do documento, use metadata para filtrar informações sensíveis, e adicione camadas de validação antes de retornar respostas.