- Data Hackers Newsletter
- Posts
- RAG: Conheça técnicas de Chunking com Haystack e LangChain
RAG: Conheça técnicas de Chunking com Haystack e LangChain
Conheça as práticas para deixar um pipeline RAG pronto para produção, desde a escolha do framework até estratégias avançadas de chunking e deployment
Data Hackers
20 de fevereiro de 2026
A Retrieval-Augmented Generation (RAG) representa uma arquitetura de IA revolucionária que combina recuperação clássica de informações com modelos generativos de linguagem (LLMs) em um único pipeline. Em vez de depender apenas do conhecimento estático pré-treinado em um LLM - que pode estar incompleto ou desatualizado - a RAG aumenta dinamicamente o processo de geração ao injetar informações recuperadas de fontes externas. O resultado é uma geração mais precisa e contextualmente relevante.
Embora o conceito por trás de um pipeline RAG seja relativamente simples, torná-lo pronto para produção pode ser complexo. Este guia técnico explora as melhores práticas, desde a escolha do framework até estratégias avançadas de chunking e deployment.

Principais pontos de atenção
Pipelines RAG aumentam as respostas dos LLMs com informações recuperadas em tempo real para respostas mais precisas
Haystack oferece pipelines modulares prontos para produção, enquanto LangChain se destaca em prototipagem e integrações com outras ferramentas
A seleção do vector database correto (FAISS, ChromaDB, Pinecone) determina escalabilidade, velocidade e recursos do sistema
O modelo de embedding e a estratégia de chunking afetam diretamente a qualidade da recuperação e da resposta final
Operacionalizar um pipeline RAG em ambientes de produção requer abordagens especializadas, avaliação, monitoramento e estratégias de deployment adequadas
Entendendo a arquitetura RAG
Um pipeline RAG geralmente possui vários componentes que interagem entre si. Os blocos de construção mais essenciais são:
Data Ingestion & Preprocessing: Fontes de conhecimento em vários formatos (documentos, páginas web, PDFs) são carregadas e preprocessadas
Chunking: Cada documento é dividido em pedaços menores semanticamente significativos
Embedding Generation: Cada chunk é transformado em um vetor de alta dimensionalidade usando um modelo de linguagem
Vector Database: Armazena todos os embeddings de chunks enquanto suporta busca por similaridade
Retrieval Engine: Ao receber uma consulta do usuário, busca os top-k chunks mais similares no banco de dados vetorial
Generation Pipeline: Um LLM recebe a consulta do usuário e os chunks de contexto recuperados para gerar uma resposta bem informada

Comparação de frameworks: Haystack vs LangChain
Para quem está construindo RAG em aplicações de produção, frameworks de alto nível são frequentemente preferidos. Haystack (da Deepset) e LangChain são as ferramentas mais populares nesta categoria.
Haystack: arquitetura centrada em pipeline
Haystack é um framework open-source focado em RAG e outros casos de uso para LLMs. Sua característica central é a arquitetura modular centrada em pipeline. Haystack adota uma abordagem baseada em grafos, onde cada componente representa um nó em um pipeline de grafo acíclico direcionado (DAG).
Vantagem principal | Descrição |
|---|---|
Design de pipeline modular | A modularidade permite trocar componentes facilmente sem reescrever toda a aplicação |
Recursos prontos para produção | Suporte integrado para avaliação, monitoramento e escalabilidade com frameworks como RAGAS e DeepEval |
Documentação superior | Documentação abrangente e fácil de seguir, melhorando a velocidade de desenvolvimento |
Otimizado para RAG | Suporte nativo para técnicas como HyDE e query expansion |
Exemplo técnico (Haystack Pipeline)
# Instalação de pacotes necessários
#pip install haystack-ai openai python-dotenv
# Carregamento de variáveis de ambiente
import os
from dotenv import load_dotenv
load_dotenv()
# Imports do Haystack
from haystack import Document
from haystack import Pipeline
from haystack.document_stores.in_memory import InMemoryDocumentStore
from haystack.components.embedders import OpenAITextEmbedder, OpenAIDocumentEmbedder
from haystack.components.retrievers.in_memory import InMemoryEmbeddingRetriever
# Criação do DocumentStore
doc_store = InMemoryDocumentStore()
# Adição de documentos
documents = [
Document(content="A Torre Eiffel está localizada em Paris, França."),
Document(content="Haystack é um framework para construir aplicações NLP."),
Document(content="LangChain é frequentemente usado para construir agentes baseados em LLM."),
Document(content="RAG significa Retrieval-Augmented Generation.")
]
doc_store.write_documents(documents)
# Geração de embeddings
embedder = OpenAITextEmbedder(model="text-embedding-ada-002")
for doc in doc_store.filter_documents():
embedding = embedder.run({"text": doc.content})["embedding"]
doc.embedding = embedding
doc_store.update_documents(documents)
# Construção do pipeline
pipeline = Pipeline()
pipeline.add_component("embedder", OpenAITextEmbedder(model="text-embedding-ada-002"))
pipeline.add_component("retriever", InMemoryEmbeddingRetriever(document_store=doc_store))
pipeline.add_component("generator", OpenAIGenerator(model="gpt-3.5-turbo"))
# Conexão dos componentes
pipeline.connect("embedder.embedding", "retriever.query_embedding")
pipeline.connect("retriever.documents", "generator.documents")
# Execução com uma consulta
query = "O que é RAG em NLP?"
result = pipeline.run({"embedder": {"text": query}})
print("\nResposta:", result["generator"]["replies"][0])
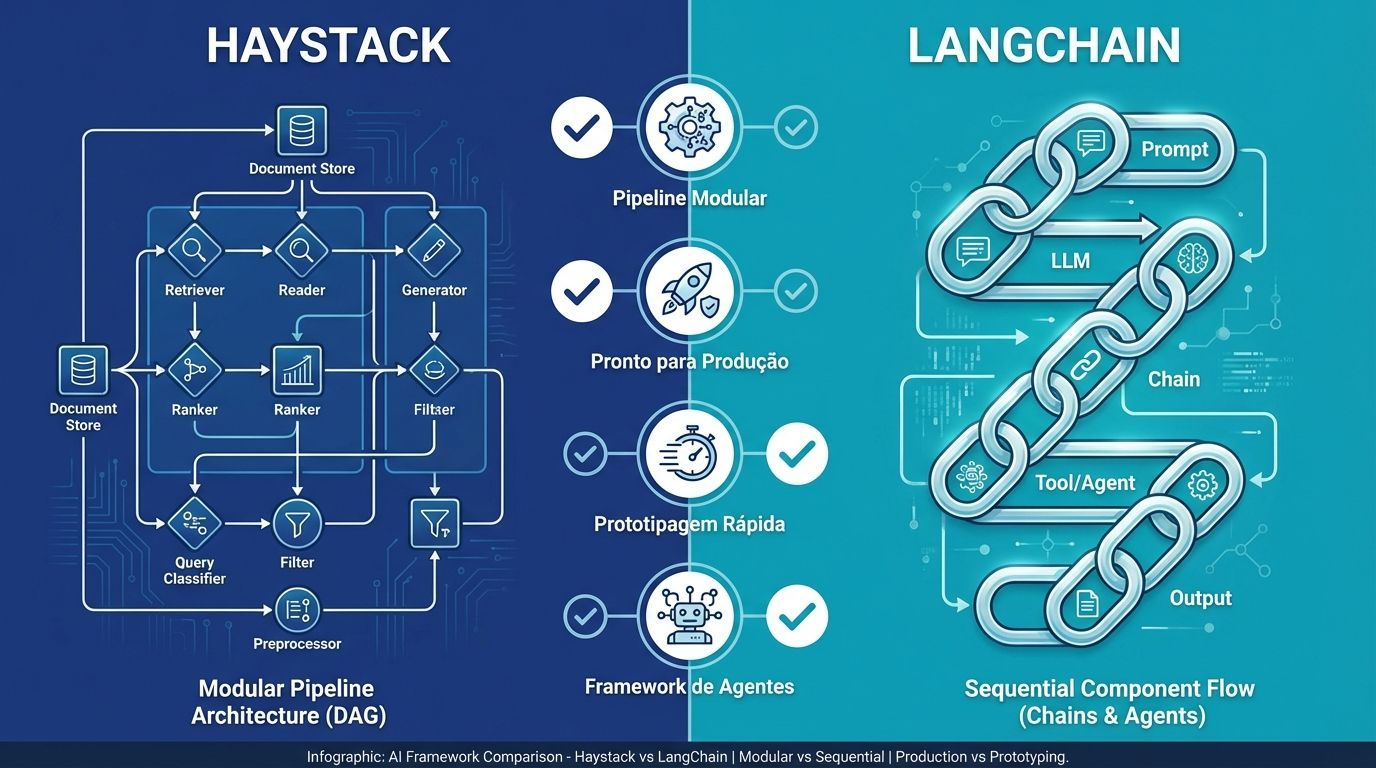
LangChain: framework baseado em chains
LangChain é outro framework open-source que ganhou popularidade para prototipagem rápida de aplicações LLM. Em vez de declarar um grafo de pipeline estático, você geralmente encadeia componentes em código.
Vantagem principal | Descrição |
|---|---|
Integrações extensivas | Compatível com vários modelos (OpenAI, Anthropic, HuggingFace) e vector databases |
Framework de agentes | Permite construir agentes que podem escolher dinamicamente quais ferramentas usar |
Prototipagem rápida | Abstrações de alto nível que lidam com casos de uso comuns |
Comunidade e ecossistema | Grande comunidade ativa com muitos tutoriais e plugins |
Exemplo técnico (LangChain RAG Chain)
# Instalação de pacotes
# pip install -qU langchain_community faiss-cpu openai python-dotenv
from langchain.vectorstores import FAISS
from langchain.embeddings import OpenAIEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.chains import RetrievalQA
from langchain.llms import OpenAI
from langchain.schema import Document
import os
from dotenv import load_dotenv
load_dotenv()
# Preparação dos documentos
raw_documents = [
"A Torre Eiffel está localizada em Paris, França.",
"Haystack é um framework para construir aplicações NLP.",
"LangChain é frequentemente usado para construir agentes baseados em LLM.",
"RAG significa Retrieval-Augmented Generation."
]
# Divisão em chunks
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500,
chunk_overlap=100
)
chunks = text_splitter.create_documents(raw_documents)
# Inicialização dos embeddings
embeddings = OpenAIEmbeddings(model="text-embedding-ada-002")
# Criação do vector store
vectorstore = FAISS.from_documents(chunks, embedding=embeddings)
# Inicialização do pipeline RetrievalQA
qa_chain = RetrievalQA.from_chain_type(
llm=OpenAI(model_name="gpt-3.5-turbo"),
retriever=vectorstore.as_retriever(search_kwargs={"k": 3}),
chain_type="stuff",
return_source_documents=True
)
# Execução de uma consulta
query = "O que é RAG em NLP?"
result = qa_chain(query)
print("\nResposta:\n", result["result"])
Quando escolher qual?
Recomendamos Haystack se seu objetivo é um sistema mantível, avaliável e pronto para produção. Se você está tentando prototipar algo rapidamente ou precisa de comportamentos complexos de agentes, LangChain pode ajudá-lo a chegar lá mais rápido.

Seleção e otimização de vector database
O vector database é um componente fundamental de qualquer pipeline RAG. Ele armazena os embeddings dos documentos e realiza buscas por similaridade. A escolha do vector store impactará no desempenho, mas também em recursos como filtragem, escalabilidade e facilidade de integração.
Vector DB | Pontos fortes | Trade-offs / Limitações | Casos de uso típicos |
|---|---|---|---|
FAISS | Biblioteca C++ com bindings Python otimizada para busca de similaridade. Suporta índices avançados e aceleração GPU | Apenas em memória - requer persistência manual e sharding | Cargas de trabalho de recuperação de baixíssima latência |
ChromaDB | Open-source com armazenamento persistente e APIs Pythonic. Excelente integração com LangChain | Limitado a uso local/in-process; falta clustering nativo | Prototipagem rápida e aplicações pequenas a médias |
Pinecone | Serviço cloud totalmente gerenciado e serverless com auto-scaling. Conjunto rico de recursos | Maior latência devido a overhead de rede. Custos de serviço | Aplicações enterprise de grande escala com mínima carga operacional |
Exemplo: desenvolvimento local com ChromaDB
Durante o desenvolvimento, você pode começar com Chroma por conveniência:
# Instalação de pacotes
#pip install langchain langchain-community chromadb pypdf tiktoken python-dotenv
import os
from langchain.vectorstores import Chroma
from langchain.embeddings import OpenAIEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import PyPDFLoader
# Configuração
OPENAI_API_KEY = os.getenv("OPENAI_API_KEY")
PERSIST_DIR = "./chroma_db"
COLLECTION_NAME = "corporate_docs"
EMBEDDING_MODEL = "text-embedding-3-large"
# Processamento de documentos
documents = PyPDFLoader("relatorio_financeiro.pdf").load()
# Chunking com consciência semântica
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=200,
separators=["\n\n", "\n", ". ", " "]
)
chunks = text_splitter.split_documents(documents)
# Inicialização de embeddings
embeddings = OpenAIEmbeddings(
model=EMBEDDING_MODEL,
openai_api_key=OPENAI_API_KEY
)
# Criação do vector store
vectorstore = Chroma(
collection_name=COLLECTION_NAME,
embedding_function=embeddings,
persist_directory=PERSIST_DIR,
client_settings={
"anonymized_telemetry": False
}
)
# Injeção de documentos
vectorstore.add_documents(
documents=chunks,
ids=[f"doc_{idx}" for idx in range(len(chunks))],
metadatas=[chunk.metadata for chunk in chunks]
)
# Operação de persistência
vectorstore.persist()
# Verificação de recuperação
query = "Projeções financeiras Q3"
results = vectorstore.similarity_search(
query=query,
k=5,
filter={"department": "finance"}
)

Estratégias de otimização de desempenho
Independentemente do vector DB escolhido, certas melhores práticas se aplicam:
Use busca aproximada para escala: A busca exata k-NN é cara e não escala bem para datasets muito grandes. Algoritmos como HNSW ou IVF podem acelerar a busca com alguma perda controlável na precisão
Considerações sobre dimensão e modelo: A busca vetorial pode ser mais lenta para embeddings de dimensões muito altas devido à maldição da dimensionalidade
Filtragem e sharding: Se seus dados estão organizados em categorias, você pode fazer shard do índice ou usar filtros, reduzindo o espaço de busca
Manter metadados: Metadados úteis podem ser armazenados com cada vetor no índice, permitindo filtragem e melhor prompting/debugging downstream
Modelos de embedding e estratégias para pipelines RAG
A escolha dos embeddings certos é uma decisão fundamental na arquitetura de qualquer pipeline RAG. Os embeddings influenciam tanto a qualidade da recuperação quanto a eficiência computacional.
OpenAI text-embedding-ada-002: um padrão confiável
Um dos modelos comerciais mais populares usados em produção tem sido o text-embedding-ada-002 da OpenAI:
Vetores de 1536 dimensões que equilibram capacidade representacional e custo computacional
Janela de contexto de 8191 tokens, permitindo processar passagens longas
Desempenho competitivo no leaderboard MTEB
Alto throughput com suporte a batching
Alternativas open-source e especializadas
Para muitas organizações, opções open-source ou self-hosted são preferíveis:
Modelos Instructor: Treinados com instruções para especializar embeddings
Família Sentence-BERT: Modelos leves e eficientes (all-MiniLM-L6-v2, all-mpnet-base-v2)
Modelos multilíngues: LaBSE, distiluse-base-multilingual-cased-v2
Modelos específicos de domínio: PubMedBERT para biomedicina, CodeBERT para código

Estratégias de chunking para recuperação otimizada
A escolha da estratégia de chunking apropriada é essencial para otimizar a precisão de recuperação e o desempenho geral do LLM em pipelines RAG.
Estratégia | Como funciona | Vantagens | Limitações |
|---|---|---|---|
Chunking de tamanho fixo | Dividir texto em chunks de tamanho igual com overlap | Simples de implementar. Contagens previsíveis | Pode quebrar sentenças/conceitos no meio |
Chunking semântico | Dividir texto com base em limites semânticos como tópicos ou parágrafos | Chunks semanticamente coerentes. Melhora precisão | Requer ferramentas NLP. Tamanho de chunk variável |
Nível de sentença (Fine-grained) | Cada chunk é uma sentença ou pequeno grupo de sentenças | Máxima precisão de recuperação | Perda de contexto mais amplo. Tamanho do índice aumenta |
Não há uma abordagem única otimizada para chunking. Sua escolha deve depender da estrutura dos seus dados, objetivos de recuperação e nível de complexidade que você pode gerenciar.
Técnicas avançadas de RAG
Além da configuração básica de "embed -> retrieve -> generate", técnicas adicionais podem ser aplicadas para otimizar um pipeline RAG:
Query Rewriting e Expansion
Query expansion aborda o problema de incompatibilidade de vocabulário query-documento criando múltiplas variações da consulta do usuário:
Workflow típico:
O usuário envia uma consulta inicial
Um LLM gera várias consultas alternativas (paráfrases, expansões)
Cada consulta gerada é roteada para o vectorstore
Os resultados são combinados para maximizar a cobertura
HyDE (Hypothetical Document Embeddings)
Em vez de embedar e buscar diretamente com a consulta do usuário, primeiro crie uma resposta/documento hipotético para a consulta usando um LLM, depois embede isso e faça a busca.
Fluxo de processo:
Gerar uma resposta hipotética usando LLM
Embedar a resposta hipotética
Usar o embedding para busca de similaridade
Recuperar documentos relevantes com base na similaridade da resposta

Avaliação e monitoramento
Métricas tradicionais de QA e busca devem se adaptar para alinhar com o contexto RAG. Nossa avaliação inclui o desempenho da etapa de recuperação e a qualidade geral das respostas.
Métricas específicas de RAG
Métricas de recuperação:
Context Recall: Proporção de documentos relevantes que foram recuperados
Context Precision: Fração de chunks recuperados que foram realmente relevantes e úteis
Contextual Relevancy Ranking: Garantir que os resultados mais relevantes sejam classificados mais alto
Métricas de geração:
Answer Relevancy: Mede se a resposta gerada é relevante para a consulta original
Faithfulness: Mede quão fiel a resposta gerada está alinhada com o contexto
Factual Correctness: Indica quão próxima a resposta está da referência
Frameworks como DeepEval e RAGAS fornecem ferramentas para computar essas métricas.
Monitoramento em produção
Além da avaliação offline, você quer monitorar o pipeline em produção:
Logs de recuperação: Registrar quais documentos foram recuperados para uma determinada consulta
Loops de feedback: Se sua aplicação suporta feedback do usuário, passe isso de volta para análise
Latência e throughput: Monitorar a duração de cada estágio
Content Drift: Se sua base de conhecimento está sujeita a mudanças, acompanhe métricas como relevância ao longo do tempo
Estratégias de deployment em produção
Deployar um pipeline RAG em produção envolve considerações de escalabilidade, segurança e confiabilidade operacional:
Área | Estratégia/Técnica | Descrição e exemplos | Considerações principais |
|---|---|---|---|
Escalabilidade e desempenho | Horizontal Scaling | Executar múltiplas réplicas do serviço RAG atrás de um load balancer | Garantir consistência do índice |
Caching | Cache de embeddings de consultas, documentos recuperados e respostas LLM | Invalidação de cache e privacidade | |
Processamento assíncrono | Usar filas de mensagens e pools de workers | Design para processamento at-least-once | |
Orquestração Kubernetes | Deploy RAG como conjunto de pods com limites de recursos | Monitorar saúde dos pods | |
Otimização de latência | Colocar serviços | Hospedar vector DB e servidores de aplicação na mesma região | Evitar hops cross-region |
LLM Warmup & Streaming | Fazer warmup de modelos LLM na inicialização | Mitiga penalidades de cold start | |
Falha e recuperação | Retries & Fallbacks | Implementar lógica de retry com exponential backoff | Garantir confiabilidade |
Segurança e privacidade | Criptografia de dados | Criptografar todos os dados em repouso e em trânsito | Compliance com regulamentações |
Controle de acesso | Marcar documentos/vetores com roles de usuário | Prevenir vazamento de dados | |
Isolamento e multi-tenancy | Usar namespaces/collections por cliente | Simplifica compliance | |
Filtragem de conteúdo | Aplicar filtragem de saída ou moderação | Reduz risco de vazamentos |

Perguntas frequentes
O que é Retrieval-Augmented Generation (RAG) e por que devo me importar?
RAG é uma arquitetura de IA poderosa que combina recuperação clássica de informações com large language models para gerar respostas aumentadas com conhecimento externo atualizado. São mais factualmente precisas e contextualmente relevantes do que LLMs isolados.
Como decido entre Haystack e LangChain para construir um pipeline RAG?
Escolha Haystack se você precisa de um pipeline pronto para produção, modular e avaliável com documentação abrangente. Escolha LangChain para prototipagem rápida de novos modelos, construção de workflows baseados em agentes ou integrações mais flexíveis.
Qual é o papel do vector database em um pipeline RAG?
O vector database armazena os embeddings de alta dimensionalidade dos seus documentos e habilita busca eficiente por similaridade para recuperar o contexto mais relevante para informar a resposta do LLM.
Quais são os melhores vector databases para pipelines RAG?
FAISS: Open-source, extremamente rápido para recuperação em memória. Ideal para setups locais menores
ChromaDB: Open-source, fácil de usar, suporta persistência e metadata. Bom para workloads locais ou pequenas/médias de produção
Pinecone/Weaviate/Azure Cognitive Search: Serviços cloud gerenciados com recursos ricos. Adequados para workloads enterprise grandes e distribuídas
Conclusão
Engenheirar um pipeline RAG pronto para produção requer consideração cuidadosa de múltiplas camadas. O sucesso depende de fazer as escolhas certas em cada etapa, desde selecionar o framework apropriado, modelos de embedding, vector databases, estratégias de chunking, práticas de avaliação, deployment e medidas de segurança.
Ao engenheirar meticulosamente cada camada do pipeline e seguir as melhores práticas em escalabilidade, monitoramento e segurança, você pode entregar soluções RAG precisas, confiáveis e seguras. Como o cenário das tecnologias RAG está evoluindo rapidamente, manter flexibilidade e avaliar continuamente os componentes do seu pipeline é essencial para manter uma solução eficaz e preparada para o futuro.