- Data Hackers Newsletter
- Posts
- RAG: Como escolher o melhor modelo de embedding
RAG: Como escolher o melhor modelo de embedding
Um guia completo com tudo o que você precisa saber para selecionar o modelo de embedding ideal para cada caso de uso
Data Hackers
20 de fevereiro de 2026
A escolha do modelo de embedding certo é uma decisão crítica que impacta enormemente o sucesso de sistemas RAG (Retrieval-Augmented Generation). Embeddings de baixa qualidade levam a recuperações ruins e, consequentemente, respostas imprecisas. Neste guia completo, vamos explorar tudo o que você precisa saber para selecionar o modelo de embedding ideal para seu caso de uso.
O que são embeddings?
Embeddings são representações vetoriais de texto em um espaço de alta dimensionalidade. Pense neles como uma lista mágica de números flutuantes que servem como coordenadas em um espaço semântico, capturando as relações entre palavras e conceitos. No contexto de Large Language Models (LLMs), os embeddings desempenham um papel fundamental na recuperação do contexto correto para sistemas RAG.
Por que você precisa de embeddings?
Embeddings formam a base para alcançar resultados precisos e contextualmente relevantes de LLMs em diferentes tarefas. Vamos explorar as diversas aplicações onde os embeddings desempenham um papel indispensável.
Question answering (perguntas e respostas)
Embeddings desempenham um papel crucial no aprimoramento do desempenho de sistemas de Question Answering (QA) dentro de aplicações RAG. Ao codificar perguntas e possíveis respostas em vetores de alta dimensionalidade, os embeddings permitem a recuperação eficiente de informações relevantes. A compreensão semântica capturada pelos embeddings facilita a correspondência precisa entre consultas e contexto, permitindo que o sistema QA forneça respostas mais precisas e contextualmente relevantes.
Busca conversacional
Conversas envolvem contextos dinâmicos e em evolução, e os embeddings ajudam a representar as nuances e relações dentro do diálogo. Ao codificar tanto as consultas do usuário quanto as respostas do sistema, os embeddings permitem que o sistema RAG recupere informações relevantes e gere respostas conscientes do contexto.
InContext Learning (ICL)
A eficácia do modelo no InContext Learning depende muito da escolha de demonstrações few-shot. Tradicionalmente, um conjunto fixo de demonstrações era empregado, limitando a adaptabilidade do modelo. Em vez de depender de um conjunto predeterminado de exemplos, essa nova abordagem envolve recuperar demonstrações relevantes ao contexto de cada consulta de entrada. A implementação dessa recuperação de demonstração é relativamente simples, utilizando bancos de dados e sistemas de recuperação existentes. Essa abordagem dinâmica melhora a eficiência e escalabilidade do processo de aprendizado e aborda vieses inerentes à seleção manual de exemplos.
Busca de ferramentas (tool fetching)
A busca de ferramentas envolve recuperar ferramentas ou recursos relevantes com base em consultas ou necessidades do usuário. Os embeddings codificam a semântica tanto da solicitação do usuário quanto das ferramentas disponíveis, permitindo que o sistema RAG execute recuperação eficaz e apresente ferramentas contextualmente relevantes. O uso de embeddings melhora a precisão das recomendações de ferramentas, contribuindo para uma experiência mais eficiente e amigável ao usuário.
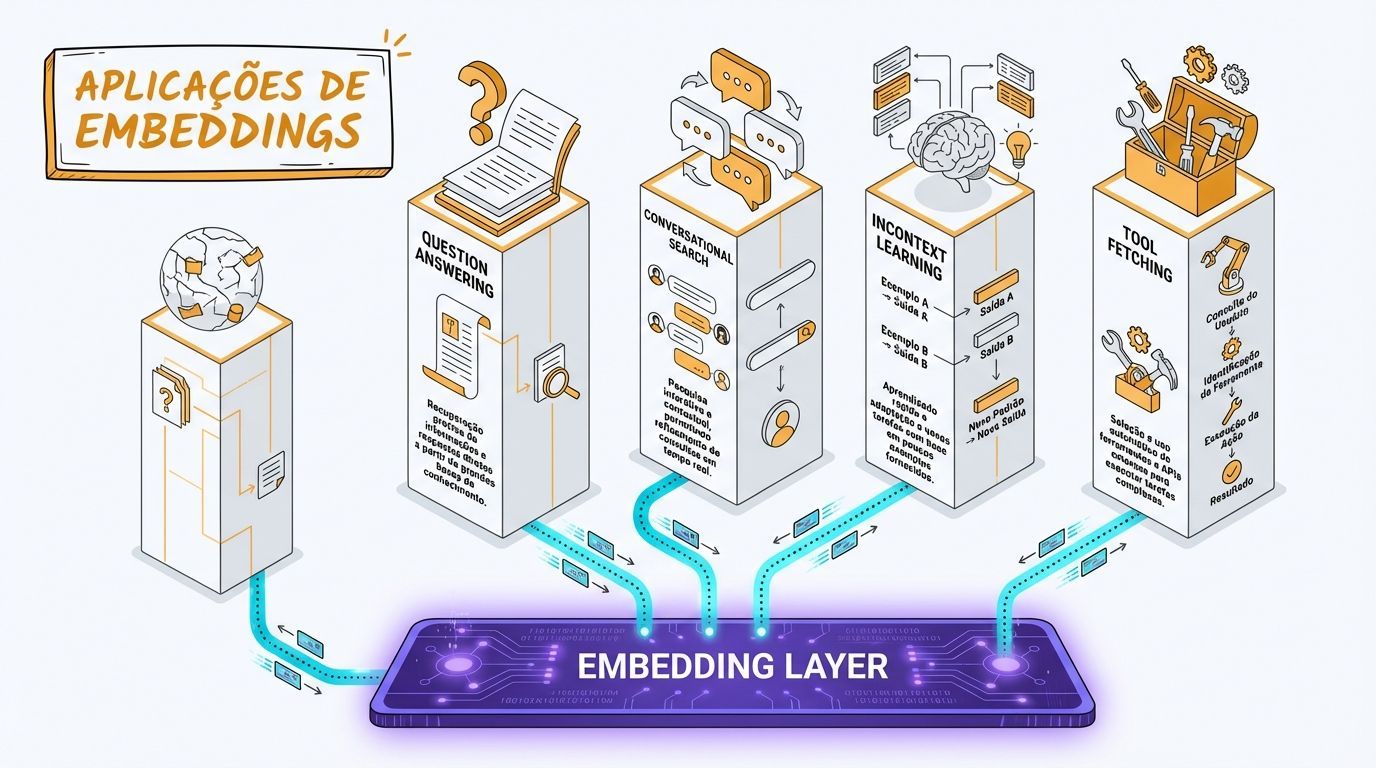
Impacto dos embeddings no desempenho do RAG
Qual encoder você seleciona para gerar embeddings é uma decisão crítica que impacta enormemente o sucesso geral do sistema RAG. Embeddings de baixa qualidade levam a recuperações ruins. Vamos revisar alguns dos critérios de seleção a considerar antes de tomar sua decisão.
Dimensão do vetor e avaliação de desempenho
Ao selecionar um modelo de embedding, considere a dimensão do vetor, desempenho médio de recuperação e tamanho do modelo. O Massive Text Embedding Benchmark (MTEB) fornece insights sobre modelos de embedding populares da OpenAI, Cohere e Voyager, entre outros. No entanto, a avaliação personalizada em seu dataset é essencial para uma avaliação precisa de desempenho.
Modelo de embedding privado vs. público
Embora o modelo de embedding forneça facilidade de uso, ele implica certas compensações. A API de embedding privada, em particular, oferece alta disponibilidade sem a necessidade de engenharia complexa de hospedagem de modelos. No entanto, essa conveniência é contrabalançada por limitações de escala. É crucial verificar os limites de taxa e explorar opções para aumentá-los. Além disso, uma vantagem notável é que as melhorias do modelo não custam nada extra. Empresas como OpenAI, Cohere e Voyage lançam consistentemente modelos de embedding aprimorados. Basta executar seu benchmark para o novo modelo e implementar uma pequena mudança na API, tornando o processo excepcionalmente conveniente.
Considerações de custo
Custo de consulta
Garanta alta disponibilidade do serviço de API de embedding, considerando fatores como tamanho do modelo e necessidades de latência. A OpenAI e provedores similares oferecem APIs confiáveis, enquanto modelos de código aberto podem exigir esforços de engenharia adicionais.
Custo de indexação
O custo de indexação de documentos é influenciado pelo serviço de encoder escolhido. O armazenamento separado de embeddings é aconselhável para flexibilidade na redefinição de serviços ou reindexação.
Custo de armazenamento
O custo de armazenamento escala linearmente com a dimensão, e a escolha de embeddings, como os da OpenAI em 1526 dimensões, impacta o custo geral. Calcule unidades médias por documento para estimar o custo de armazenamento.
Latência de busca
A latência da busca semântica cresce com a dimensão dos embeddings. Opte por embeddings de baixa dimensionalidade para minimizar a latência.
Suporte a idiomas
Escolha um encoder multilíngue ou use um sistema de tradução junto com um encoder de inglês para suportar idiomas não ingleses.
Preocupações com privacidade
Requisitos rigorosos de privacidade de dados, especialmente em domínios sensíveis como finanças e saúde, podem influenciar a escolha dos serviços de embedding. Avalie considerações de privacidade antes de selecionar um provedor.
Granularidade do texto
Vários níveis de granularidade, incluindo representações no nível de palavras, sentenças e documentos, influenciam a profundidade da informação semântica incorporada. Por exemplo, otimizar relevância e minimizar ruído no processo de embedding pode ser alcançado segmentando texto grande em chunks menores. Devido ao tamanho de vetor limitado disponível para armazenar informações textuais, os embeddings tornam-se ruidosos com texto mais longo.

Tipos de embeddings
Diferentes tipos de embeddings são projetados para abordar desafios e requisitos únicos em diferentes domínios. Desde embeddings densos capturando significado semântico geral até embeddings esparsos enfatizando informações específicas, e desde embeddings multi-vetoriais com interação tardia até embeddings inovadores de dimensão variável, conhecer seu caso de uso ajudará a decidir qual tipo de embedding empregar.
Dense embeddings (embeddings densos)
Embeddings densos são vetores contínuos de valores reais que representam informações em um espaço de alta dimensionalidade. No contexto de aplicações RAG, embeddings densos, como aqueles gerados por modelos como Ada da OpenAI ou sentence transformers, contêm valores diferentes de zero para cada elemento. Esses embeddings se concentram em capturar o significado semântico geral de palavras ou frases, tornando-os adequados para tarefas como recuperação densa, que envolvem mapear texto em um único embedding. Isso ajuda a corresponder e classificar documentos de forma eficaz com base na similaridade de conteúdo.
Modelos de recuperação densa utilizam busca aproximada de vizinhos mais próximos para recuperar eficientemente documentos relevantes para várias aplicações. Esses são os embeddings geralmente referidos para busca semântica e bancos de dados vetoriais.
Sparse embeddings (embeddings esparsos)
Embeddings esparsos, por outro lado, são representações onde a maioria dos valores é zero, enfatizando apenas informações relevantes. Em aplicações RAG, vetores esparsos são essenciais para cenários com muitas palavras-chave raras ou termos especializados. Ao contrário dos vetores densos que contêm valores diferentes de zero para cada elemento, vetores esparsos se concentram em pesos relativos de palavras por documento, resultando em um sistema mais eficiente e interpretável.
Vetores esparsos como SPLADE são especialmente benéficos em domínios com terminologias específicas, como o campo médico, onde muitos termos raros podem não estar presentes no vocabulário geral. O uso de embeddings esparsos ajuda a superar as limitações dos modelos Bag-of-Words (BOW), abordando o problema de incompatibilidade de vocabulário.
Multi-vector embeddings (embeddings multi-vetoriais)
Modelos de embedding multi-vetoriais como ColBERT apresentam interação tardia, onde a interação entre representações de consulta e documento ocorre tardiamente no processo, depois que ambos foram codificados independentemente. Essa abordagem contrasta com modelos de interação precoce, onde embeddings de consulta e documento interagem em estágios anteriores, potencialmente levando ao aumento da complexidade computacional.
O design de interação tardia permite a pré-computação de representações de documentos, contribuindo para tempos de recuperação mais rápidos e demandas computacionais reduzidas, tornando-o mais adequado para processar grandes coleções de documentos.
Long context embeddings (embeddings de contexto longo)
Documentos longos sempre representaram um desafio particular para modelos de embedding. A limitação nos comprimentos máximos de sequência, muitas vezes enraizada em arquiteturas como BERT, leva os praticantes a segmentar documentos em chunks menores. Infelizmente, essa segmentação pode resultar em significados semânticos fragmentados e má representação de parágrafos inteiros. Além disso, aumenta o uso de memória, demandas computacionais durante buscas vetoriais e latências.
Modelos como BGE-M3 tornam possível codificar sequências de até 8.192 tokens, o que ajuda a reduzir o armazenamento de vetores e a latência sem muita perda no desempenho de recuperação.
Variable dimension embeddings (embeddings de dimensão variável)
Embeddings de dimensão variável são um conceito único construído sobre Matryoshka Representation Learning (MRL). O MRL aprende embeddings de dimensões mais baixas que são aninhados no embedding original, semelhante a uma série de Bonecas Matryoshka. Cada representação fica dentro de uma maior, da menor à maior "boneca". Essa hierarquia de subespaços aninhados é aprendida pelo MRL, e ele empacota eficientemente informações em granularidades logarítmicas.
A hipótese é que o MRL impõe uma estrutura de subespaço vetorial, onde cada vetor de representação aprendido está em um espaço vetorial de dimensão inferior que é um subespaço de um espaço vetorial maior. Modelos como text-embedding-3-small da OpenAI e Embed v1.5 da Nomic são treinados usando MRL e oferecem ótimo desempenho mesmo em dimensões de embedding pequenas de 256.
Code embeddings (embeddings de código)
Embeddings de código são um desenvolvimento recente usado para integrar capacidades alimentadas por IA em Ambientes de Desenvolvimento Integrados (IDEs), transformando fundamentalmente como os desenvolvedores interagem com bases de código. Ao contrário da busca de texto tradicional, o embedding de código oferece compreensão semântica, permitindo interpretar a intenção por trás de consultas relacionadas a trechos de código ou funcionalidades.
Embeddings de código como text-embedding-3-small da OpenAI e jina-embeddings-v2-base-code facilitam a busca através do código, construção de documentação automatizada e criação de assistência de código baseada em chat.

Como medir o desempenho de embeddings
Métricas de recuperação nos ajudam a medir o desempenho de embeddings, lideradas pelo amplamente reconhecido benchmark MTEB. Cada dataset na avaliação de recuperação compreende um corpus, consultas e um mapeamento associando cada consulta com documentos relevantes do corpus. O objetivo é identificar esses documentos pertinentes. O modelo fornecido é empregado para embedar todas as consultas e documentos do corpus, e então as pontuações de similaridade são calculadas usando similaridade de cosseno. Posteriormente, os documentos do corpus são classificados para cada consulta com base nessas pontuações, e métricas como nDCG@10 são calculadas.
Embora o MTEB forneça insights sobre alguns dos melhores modelos de embedding, ele falha em determinar a escolha ideal para domínios ou tarefas específicas. Como resultado, é vital conduzir uma avaliação em seu próprio dataset. Frequentemente, possuímos texto bruto e visamos avaliar o desempenho do RAG em consultas de usuários. Em tais cenários, métricas como chunk attribution podem ser bastante úteis.
Chunk attribution identifica quais chunks ou documentos recuperados foram realmente utilizados pelo modelo para gerar uma resposta. Uma pontuação de atribuição de 0 indica que a recuperação foi incapaz de buscar os documentos necessários para responder à pergunta. A pontuação média representa a proporção de chunks utilizados (em float) em um nível de execução.
Escolhendo o modelo de embedding certo
Vamos explorar como podemos utilizar chunk attribution para escolher o modelo de embedding ideal para nosso sistema RAG. Podemos identificar qual modelo de embedding é mais adequado para nosso caso de uso atribuindo chunks recuperados a saídas geradas.
Preparação de dados
Primeiro, vamos recuperar relatórios 10-K da Nvidia dos últimos quatro anos. Realizamos uma análise direta usando a biblioteca PyPDF, produzindo chunks grandes sem aplicar técnicas avançadas de chunking. Este processo resulta em aproximadamente 700 chunks de texto consideráveis.
import glob
from langchain_community.document_loaders import PyPDFLoader
documents = []
for file_path in glob.glob("../data/nvidia_10k_*.pdf"):
print(file_path)
loader = PyPDFLoader(file_path)
documents.extend(loader.load_and_split())
len(documents)
Para testar nosso sistema RAG, precisamos de um conjunto de perguntas. Aproveitando o GPT-turbo com um prompt de instrução zero-shot, geramos uma pergunta para cada chunk de texto.
from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage
def get_questions(text):
questions = chat_model.invoke([
HumanMessage(
content=f"""Your job is to generate only 1 short question from the given text such that it can be answered using the provided text. Use the exact info in the questions as mentioned in the text. Return questions starting with - instead of numbers.
Text: {text}
Questions: """
)
])
questions = questions.content.replace("- ", "").split("\n")
questions = list(filter(None, questions))
return questions
Selecionamos aleatoriamente 100 chunks do pool de 700 e criamos perguntas de acordo para ter algumas perguntas de cada relatório anual.

QA Chain
Com os dados preparados, definimos nossa RAG chain usando Langchain, incorporando o índice vetorial serverless Pinecone e GPT como gerador.
import os
from langchain_openai import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain.schema.runnable import RunnablePassthrough
from langchain.schema import StrOutputParser
from langchain_community.vectorstores import Pinecone as langchain_pinecone
from pinecone import Pinecone
def get_qa_chain(embeddings, index_name, k, llm_model_name, temperature):
pc = Pinecone(api_key=os.getenv("PINECONE_API_KEY"))
index = pc.Index(index_name)
vectorstore = langchain_pinecone(index, embeddings.embed_query, "text")
retriever = vectorstore.as_retriever(search_kwargs={"k": k})
rag_prompt = ChatPromptTemplate.from_messages([
("system", "Answer the question based only on the provided context."),
("human", "Context: '{context}' \n\n Question: '{question}'"),
])
llm = ChatOpenAI(model_name=llm_model_name, temperature=temperature, tiktoken_model_name="cl100k_base")
def format_docs(docs):
return "\n\n".join([d.page_content for d in docs])
rag_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| rag_prompt
| llm
| StrOutputParser()
)
return rag_chain
Métricas de avaliação RAG
Definimos as métricas a serem calculadas para cada execução:
Métricas RAG:
Chunk Attribution: Métrica booleana que mede se um 'chunk' foi usado para compor a resposta
Chunk Utilization: Métrica float que mede quanto do texto do chunk foi usado para compor a resposta
Completeness: Métrica de resposta medindo quanto do contexto fornecido foi usado para gerar uma resposta
Context Adherence: Métrica de resposta que mede se a saída do LLM adere ao contexto fornecido
Métricas de segurança:
PII (Private Identifiable Information): Identifica instâncias de PII nas respostas
Toxicity: Sinaliza se uma resposta contém informações tóxicas ou de ódio
Tone: Classifica o tom da resposta em 9 categorias diferentes de emoção
Métricas de sistema:
Latency: Rastreia a latência das chamadas LLM
Workflow
Finalmente, criamos uma função que executa com vários parâmetros de sweep, permitindo-nos experimentar com diferentes modelos de embedding para testar nosso caso de uso e identificar o ideal.
from langchain_openai import OpenAIEmbeddings
from langchain_community.embeddings import HuggingFaceEmbeddings
def rag_chain_executor(emb_model_name: str, dimensions: int, llm_model_name: str, k: int) -> None:
if "text-embedding-3" in emb_model_name:
embeddings = OpenAIEmbeddings(model=emb_model_name, dimensions=dimensions)
else:
embeddings = HuggingFaceEmbeddings(model_name=emb_model_name, encode_kwargs={'normalize_embeddings': True})
Sweep e resultados
Experimentamos com três modelos de dimensões similares para garantir poder de expressividade comparável. Um desses modelos é all-MiniLM-L6-v2, um conhecido modelo de embedding com 384 dimensões. Além disso, utilizamos as APIs de embedding da OpenAI recém-lançadas, nomeadamente text-embedding-3-small e text-embedding-3-large.
Os resultados mostram que mudar do encoder all-MiniLM-L6-v2 para o encoder text-embedding-3-small resulta em um aumento de 7% na atribuição. Isso sugere que os encoders text-embedding-3-small nos permitem recuperar chunks mais valiosos. O desempenho de ambos small e large é quase idêntico, indicando que prosseguir com o small ajudaria a economizar dinheiro mantendo o desempenho.

Conclusão
Esperamos que este guia tenha lhe dado uma compreensão abrangente dos fatores críticos que influenciam a seleção de embeddings. Reconhecer os vários tipos de embeddings e entender o que funciona melhor para você é essencial para RAG pronto para produção.
A escolha do modelo de embedding certo pode fazer a diferença entre um sistema RAG que fornece respostas precisas e contextualmente relevantes e um que falha em recuperar informações úteis. Ao considerar cuidadosamente fatores como dimensionalidade, custo, latência, suporte a idiomas e privacidade, e ao realizar avaliações adequadas com métricas como chunk attribution, você pode tomar decisões informadas que otimizam o desempenho do seu sistema RAG.
Lembre-se: não existe uma solução única para todos os casos. O melhor modelo de embedding para seu caso de uso dependerá de suas necessidades específicas, restrições e do domínio em que você está trabalhando. Experimente, avalie e itere para encontrar a solução ideal.