- Data Hackers Newsletter
- Posts
- Prompt Caching: o que é e como utilizar com API do Claude
Prompt Caching: o que é e como utilizar com API do Claude
Aprenda a reutilizar partes específicas de seus prompts e reduza os custos e o tempo de processamento
Data Hackers
21 de fevereiro de 2026

Prompt caching é um recurso poderoso que otimiza o uso da API do Claude, permitindo que você reutilize partes específicas de seus prompts. Essa abordagem reduz significativamente o tempo de processamento e os custos para tarefas repetitivas ou prompts com elementos consistentes.
Neste guia completo, vamos explorar como o prompt caching funciona, seus benefícios, implementação prática e melhores práticas para maximizar sua eficiência ao trabalhar com os modelos Claude.
Como funciona o prompt caching
Quando você envia uma requisição com prompt caching habilitado, o sistema segue este fluxo:
Verifica se um prefixo do prompt já está em cache de uma consulta recente
Se encontrado, utiliza a versão cacheada, reduzindo tempo de processamento e custos
Caso contrário, processa o prompt completo e cacheia o prefixo assim que a resposta começa
Por padrão, o cache tem duração de 5 minutos e é atualizado sem custo adicional cada vez que o conteúdo cacheado é utilizado. Para casos que exigem maior duração, a Anthropic também oferece cache de 1 hora com custo adicional.

Casos de uso ideais para prompt caching
O prompt caching é especialmente útil em cenários como:
Prompts com múltiplos exemplos: Quando você inclui diversos exemplos para melhorar as respostas do Claude
Grande quantidade de contexto: Documentos extensos ou informações de background
Tarefas repetitivas: Instruções consistentes que se repetem em múltiplas requisições
Conversas longas: Diálogos multi-turno com contexto extenso
Assistentes de código: Manutenção de seções relevantes do codebase no prompt
Processamento de documentos: Incorporação de material completo, incluindo imagens
Uso de ferramentas (tool use): Cenários com múltiplas chamadas de ferramentas
Implementação básica
Aqui está um exemplo prático de como implementar prompt caching usando o bloco cache_control:
import anthropic
client = anthropic.Anthropic()
response = client.messages.create(
model="claude-opus-4-6",
max_tokens=1024,
system=[
{
"type": "text",
"text": "Você é um assistente de IA especializado em análise literária. Seu objetivo é fornecer comentários perspicazes sobre temas, personagens e estilo de escrita."
},
{
"type": "text",
"text": "<conteúdo completo de Orgulho e Preconceito>",
"cache_control": {"type": "ephemeral"}
}
],
messages=[
{
"role": "user",
"content": "Analise os principais temas em Orgulho e Preconceito."
}
]
)
Neste exemplo, o texto completo de "Orgulho e Preconceito" é cacheado usando o parâmetro cache_control. Isso permite reutilizar este texto extenso em múltiplas chamadas da API sem reprocessá-lo a cada vez.

Estrutura de preços
O prompt caching introduz uma nova estrutura de preços. Veja a tabela com os modelos suportados:
Modelo | Tokens de Entrada Base | Cache Writes (5m) | Cache Writes (1h) | Cache Hits & Refreshes | Tokens de Saída |
|---|---|---|---|---|---|
Claude Opus 4.6 | $5 / MTok | $6.25 / MTok | $10 / MTok | $0.50 / MTok | $25 / MTok |
Claude Sonnet 4.5 | $3 / MTok | $3.75 / MTok | $6 / MTok | $0.30 / MTok | $15 / MTok |
Claude Haiku 4.5 | $1 / MTok | $1.25 / MTok | $2 / MTok | $0.10 / MTok | $5 / MTok |
Claude Haiku 3.5 | $0.80 / MTok | $1 / MTok | $1.6 / MTok | $0.08 / MTok | $4 / MTok |
Claude Haiku 3 | $0.25 / MTok | $0.30 / MTok | $0.50 / MTok | $0.03 / MTok | $1.25 / MTok |
Multiplicadores de preço:
Tokens de escrita em cache (5 minutos): 1.25x o preço base
Tokens de escrita em cache (1 hora): 2x o preço base
Tokens de leitura do cache: 0.1x o preço base
Estruturando seu prompt para caching
Para otimizar o uso do prompt caching, siga estas diretrizes:
Hierarquia de cacheamento
O cache segue a hierarquia: tools → system → messages. Esta ordem forma uma hierarquia onde cada nível se baseia nos anteriores.
Coloque conteúdo estático (definições de ferramentas, instruções do sistema, contexto, exemplos) no início do seu prompt. Marque o final do conteúdo reutilizável com o parâmetro cache_control.
Como funciona a verificação automática de prefixos
Você pode usar apenas um breakpoint de cache no final do seu conteúdo estático, e o sistema automaticamente encontrará a sequência mais longa de blocos cacheados. Três princípios fundamentais:
Cache keys são cumulativos: Quando você marca explicitamente um bloco com
cache_control, a chave de hash do cache é gerada fazendo hash de todos os blocos anteriores sequencialmenteVerificação sequencial reversa: O sistema verifica cache hits trabalhando de trás para frente do seu breakpoint explícito
Janela de lookback de 20 blocos: O sistema verifica apenas até 20 blocos antes de cada breakpoint
cache_controlexplícito

Limitações do cache
É importante conhecer as limitações do prompt caching:
Tamanho mínimo cacheável
4096 tokens para Claude Opus 4.6, Claude Opus 4.5 e Claude Haiku 4.5
1024 tokens para Claude Sonnet 4.5, Claude Opus 4.1, Claude Opus 4 e Claude Sonnet 4
2048 tokens para Claude Haiku 3.5 e Claude Haiku 3
Prompts mais curtos não podem ser cacheados, mesmo se marcados com cache_control.
O que pode ser cacheado
Definições de ferramentas no array
toolsMensagens do sistema no array
systemBlocos de conteúdo em
messages.content(turnos de usuário e assistente)Imagens e documentos em
messages.contentUso de ferramentas e resultados de ferramentas
O que não pode ser cacheado
Thinking blocks não podem ser cacheados diretamente, mas podem ser cacheados junto com outro conteúdo quando aparecem em turnos anteriores do assistente
Sub-blocos de conteúdo (como citações)
Blocos de texto vazios
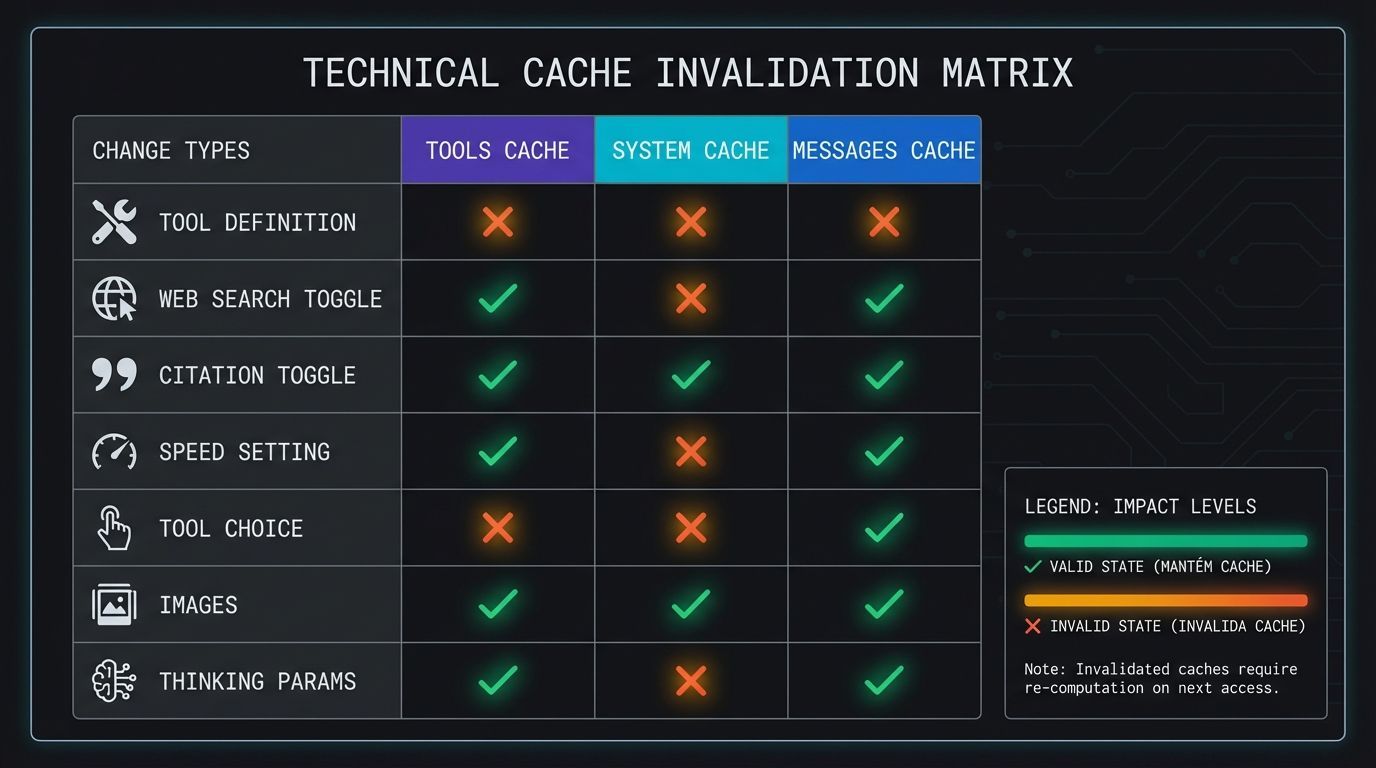
O que invalida o cache
Modificações no conteúdo cacheado podem invalidar parte ou todo o cache:
Tipo de Mudança | Tools Cache | System Cache | Messages Cache | Impacto |
|---|---|---|---|---|
Definições de ferramentas | ✘ | ✘ | ✘ | Modificar definições invalida todo o cache |
Toggle de web search | ✓ | ✘ | ✘ | Ativar/desativar web search modifica o system prompt |
Toggle de citações | ✓ | ✘ | ✘ | Ativar/desativar citações modifica o system prompt |
Configuração de velocidade | ✓ | ✘ | ✘ | Alternar entre fast mode e velocidade padrão invalida caches |
Tool choice | ✓ | ✓ | ✘ | Mudanças no parâmetro tool_choice afetam apenas message blocks |
Imagens | ✓ | ✓ | ✘ | Adicionar/remover imagens afeta message blocks |
Parâmetros de thinking | ✓ | ✓ | ✘ | Mudanças em extended thinking afetam message block |

Monitorando performance do cache
Monitore a performance usando estes campos na resposta da API:
cache_creation_input_tokens: Número de tokens escritos no cache ao criar uma nova entradacache_read_input_tokens: Número de tokens recuperados do cache para esta requisiçãoinput_tokens: Número de tokens de entrada que não foram lidos ou usados para criar cache
Calculando tokens totais de entrada
Para calcular o total de tokens de entrada:
total_input_tokens = cache_read_input_tokens + cache_creation_input_tokens + input_tokens
Exemplo prático: Se você tem uma requisição com 100.000 tokens de conteúdo cacheado (lidos do cache), 0 tokens de novo conteúdo sendo cacheado, e 50 tokens na sua mensagem de usuário:
cache_read_input_tokens: 100.000cache_creation_input_tokens: 0input_tokens: 50Total de tokens de entrada processados: 100.050 tokens
Melhores práticas para caching efetivo
Para otimizar a performance do prompt caching:
Cachear conteúdo estável e reutilizável: Instruções do sistema, informações de background, contextos grandes ou definições frequentes de ferramentas
Posicionar conteúdo cacheado no início: Coloque o conteúdo a ser cacheado no começo do prompt
Usar breakpoints estrategicamente: Separe diferentes seções cacheaveis do prefixo
Definir breakpoints no final das conversas: Maximiza taxa de cache hits, especialmente com mais de 20 blocos de conteúdo
Analisar regularmente: Monitore as taxas de cache hit e ajuste sua estratégia conforme necessário
Cache de 1 hora: quando usar
Se 5 minutos é muito curto, a Anthropic oferece cache de 1 hora com custo adicional. Para usar o cache estendido, inclua ttl na definição cache_control:
"cache_control": {
"type": "ephemeral",
"ttl": "1h" # ou "5m"
}
Cenários ideais para cache de 1 hora
Prompts usados com frequência menor que 5 minutos, mas maior que 1 hora
Quando agentes secundários levam mais de 5 minutos
Quando a latência é importante e respostas podem levar mais de 5 minutos
Para melhorar utilização de rate limits, já que cache hits não contam contra seu limite
Exemplos práticos
Cacheando definições de ferramentas
response = client.messages.create(
model="claude-opus-4-6",
max_tokens=1024,
tools=[
{
"name": "get_weather",
"description": "Obtém informações do tempo para uma localização",
"input_schema": {
"type": "object",
"properties": {
"location": {"type": "string"}
}
},
"cache_control": {"type": "ephemeral"}
}
],
messages=[
{"role": "user", "content": "Qual é o tempo em São Paulo?"}
]
)
Continuando conversas multi-turno
response = client.messages.create(
model="claude-opus-4-6",
max_tokens=1024,
system=[
{
"type": "text",
"text": "Você é um assistente especializado em Python.",
"cache_control": {"type": "ephemeral"}
}
],
messages=[
{"role": "user", "content": "Como criar uma lista em Python?"},
{"role": "assistant", "content": "Para criar uma lista..."},
{
"role": "user",
"content": "E como adicionar elementos?",
"cache_control": {"type": "ephemeral"}
}
]
)
FAQ sobre Prompt Caching
Preciso de múltiplos breakpoints de cache?
Um breakpoint no final geralmente é suficiente, pois o sistema verifica automaticamente até 20 blocos anteriores. Use múltiplos breakpoints quando quiser cachear seções que mudam em frequências diferentes ou garantir caching de conteúdo além dos 20 blocos.
Breakpoints de cache adicionam custo extra?
Não. Breakpoints em si não adicionam custo. Você paga apenas por cache writes (25% a mais que tokens de entrada base para TTL de 5 minutos) e cache reads (10% do preço de tokens de entrada base).
O cache funciona com extended thinking?
Sim, mas com comportamentos especiais. Thinking blocks não podem ser marcados explicitamente com cache_control, mas são cacheados automaticamente como parte do conteúdo da requisição em chamadas subsequentes. Quando lidos do cache, contam como tokens de entrada.
Posso usar prompt caching com Batches API?
Sim, prompt caching é totalmente compatível com a Batches API e outros recursos da API do Claude.
Como funciona privacidade e separação de dados?
A partir de 5 de fevereiro de 2026, o prompt caching usará isolamento por workspace em vez de por organização. Caches serão isolados por workspace, garantindo separação de dados entre workspaces dentro da mesma organização. Organizações diferentes nunca compartilham caches.
Conclusão
O prompt caching é um recurso essencial para otimizar custos e performance ao trabalhar com os modelos Claude. Com a estratégia certa de cacheamento, você pode reduzir significativamente tanto o tempo de resposta quanto os custos de suas aplicações, especialmente em cenários com contextos grandes ou prompts repetitivos.
Comece experimentando com casos de uso simples e vá ajustando sua estratégia conforme monitora as métricas de performance. A combinação de breakpoints estratégicos, conteúdo bem estruturado e monitoramento contínuo garantirá que você aproveite ao máximo este recurso poderoso.
Para explorar mais exemplos e implementações detalhadas, confira o cookbook de prompt caching da Anthropic com casos de uso práticos e melhores práticas.