- Data Hackers Newsletter
- Posts
- Prompt caching: como reduzir custos em até 90% com IA (guia prático com Anthropic)
Prompt caching: como reduzir custos em até 90% com IA (guia prático com Anthropic)
Entenda como armazenar e reutilizar contexto pode otimizar o desempenho de modelos IA em matéria de velocidade e custo
Data Hackers
11 de fevereiro de 2026
Construir produtos de IA responsivos é um desafio constante. Os usuários esperam respostas instantâneas, mas os large language models podem ser lentos e caros ao processar grandes volumes de conteúdo. É aqui que entra o prompt caching — uma técnica que melhora drasticamente o desempenho da IA ao armazenar e reutilizar contexto, em vez de reprocessá-lo a cada interação.
O prompt caching funciona identificando partes estáticas dos prompts e armazenando-as temporariamente. Quando os usuários fazem perguntas subsequentes, apenas a nova entrada é processada contra esse contexto armazenado. Isso reduz a latência em até 80% e corta custos em 50-90% para interações repetidas com modelos grandes como Claude e GPT.
Para equipes de produto, isso significa que você finalmente pode construir recursos de IA que eram anteriormente impraticáveis. Analise documentos inteiros, processe grandes bases de código ou crie ferramentas educacionais que respondam a perguntas sobre materiais extensos — tudo isso mantendo responsividade e controlando custos.

O que é prompt caching?
Prompt caching armazena e reutiliza instruções, inputs, consultas ou conteúdos frequentemente usados em conversas com IA. Pense nisso como lembrar o contexto de uma conversa sem ter que começar do zero cada vez. Quando você interage com sistemas de IA como Claude ou modelos GPT, o prompt caching permite que o sistema recorde informações estáticas — como documentos extensos ou instruções detalhadas — sem processá-las repetidamente.
Como funciona na prática?
O sistema de IA ou LLM identifica as partes estáticas do seu prompt e as armazena temporariamente. Quando você faz perguntas subsequentes, sua nova entrada é processada contra esse contexto armazenado. Isso reduz drasticamente o tempo de processamento e os custos.
Os benefícios são significativos:
Respostas mais rápidas: Prompts em cache reduzem a latência em até 80%, já que o sistema não reprocessa informações que já conhece
Custos menores: Você pode economizar entre 50-90% nos custos de tokens de entrada para interações repetidas
Melhor experiência do usuário: Tempos de resposta mais rápidos significam conversas mais fluidas
Comparação de performance do prompt caching
Economia de custos nos modelos OpenAI
Modelo | Economia nos tokens de texto |
|---|---|
Modelos padrão* | 50% de redução |
*exclui gpt-4o-2024-05-13 e chatgpt-4o-latest
Melhorias de performance da Anthropic por caso de uso
Caso de uso | Redução de latência | Economia de custo |
|---|---|---|
Análise de documentos | 85% | 90% |
Code review | 78% | 87% |
Atendimento ao cliente | 82% | 85% |

Como mostrado acima, o prompt caching oferece melhorias significativas de performance tanto nos modelos OpenAI quanto Anthropic. Os modelos OpenAI consistentemente apresentam 50% de redução de custos para inputs de texto, enquanto a implementação da Anthropic mostra melhorias dramáticas tanto em tempos de resposta quanto em custos em vários cenários do mundo real.
Aplicações práticas do prompt caching
Vamos imaginar que você faça upload de um livro inteiro para um assistente de IA. O prompt caching permite que você faça múltiplas perguntas sobre o conteúdo sem pagar para processar o livro inteiro cada vez. Isso torna a análise de documentos grandes, revisão de códigos ou construção de ferramentas educacionais muito mais prática.
Em aplicações do mundo real, o prompt caching se mostra valioso para:
Análise de documentos (livros, papers de pesquisa, contratos legais)
Code reviews e documentação técnica
Chatbots de atendimento ao cliente que lidam com perguntas comuns
Plataformas educacionais onde estudantes fazem perguntas sobre materiais de curso
Cada provedor de IA implementa caching de forma um pouco diferente. O Claude da Anthropic mantém prompts em cache por 5 minutos, enquanto a implementação da OpenAI mantém prefixos em cache por 5-10 minutos (ocasionalmente até uma hora durante períodos de baixa demanda).

Fundamentos técnicos e mecanismos
A arquitetura normalmente depende de armazenamento em memória para velocidade, embora algumas implementações usem soluções baseadas em disco para persistência. Basicamente, o sistema precisa recuperar rapidamente os prompts em cache sem adicionar overhead significativo.
Componentes principais
A maioria dos sistemas de prompt caching usa estes componentes-chave:
Mecanismo de busca em cache: Quando um prompt chega, o sistema verifica se existe um prefixo correspondente no cache usando algoritmos de busca eficientes
Camada de armazenamento: Mantém os prompts em cache acessíveis para recuperação rápida. Caches em memória fornecem acesso mais rápido, mas são limitados pela RAM, enquanto opções baseadas em disco oferecem persistência ao custo de velocidade
Políticas de remoção: Como o espaço em cache é limitado, algoritmos como Least Recently Used (LRU) determinam quais prompts remover quando o espaço acaba
Estruturas de dados no prompt caching
As estruturas de dados que alimentam o prompt caching incluem:
Hash tables: Para busca rápida de correspondências exatas
Vector embeddings: Permitem correspondência de similaridade para caching fuzzy
Filas de expiração baseadas em tempo: Rastreiam a atualização do cache
Para implementação em Python, você pode usar várias bibliotecas:
# Caching simples com ferramentas built-in do Python
from functools import lru_cache
@lru_cache(maxsize=100)
def process_prompt(prompt):
# Lógica de processamento aqui
return response
Implementações mais avançadas podem aproveitar o Redis para caching distribuído ou usar bibliotecas especializadas como cachetools para armazenamento eficiente de memória.

Benefícios estratégicos e de negócio
Melhorias de performance
As melhorias de velocidade são impressionantes. De acordo com a documentação da OpenAI, o prompt caching pode reduzir a latência em até 80% para prompts longos. Isso acontece porque o sistema não precisa reprocessar informações que já possui.
Na prática, isso significa:
Respostas chegam 2-3x mais rápido uma vez que o prompt está em cache
Cargas de servidor diminuem significativamente
Aplicações se tornam mais responsivas e parecem mais naturais
Por exemplo, em testes com múltiplos LLMs, incluindo Llama3, os tempos de resposta caíram de 151.79 segundos para apenas 42.48 segundos ao usar prompts em cache.
Economia de custos
Os benefícios financeiros são igualmente convincentes. O prompt caching tipicamente reduz custos ao:
Cortar despesas de tokens de entrada em 50-90% para interações repetidas
Diminuir requisitos de recursos computacionais
Permitir uso mais eficiente de orçamentos de IA
Como observado pela Anthropic, "Ao aproveitar totalmente o prompt caching dentro do seu prompt, você pode reduzir latência em >2x e custos em até 90%". Isso significa que você pode construir recursos de IA mais sofisticados sem aumentos proporcionais de custo.
Experiência do usuário aprimorada
O que isso significa para seus usuários finais? Tempos de resposta mais rápidos criam conversas que parecem mais naturais. Os usuários percebem sistemas de IA que respondem rapidamente como mais inteligentes e úteis.
Essa experiência melhorada se traduz em:
Taxas de engajamento mais altas com recursos de IA
Maior satisfação e retenção de usuários
Interações de IA mais complexas se tornando práticas
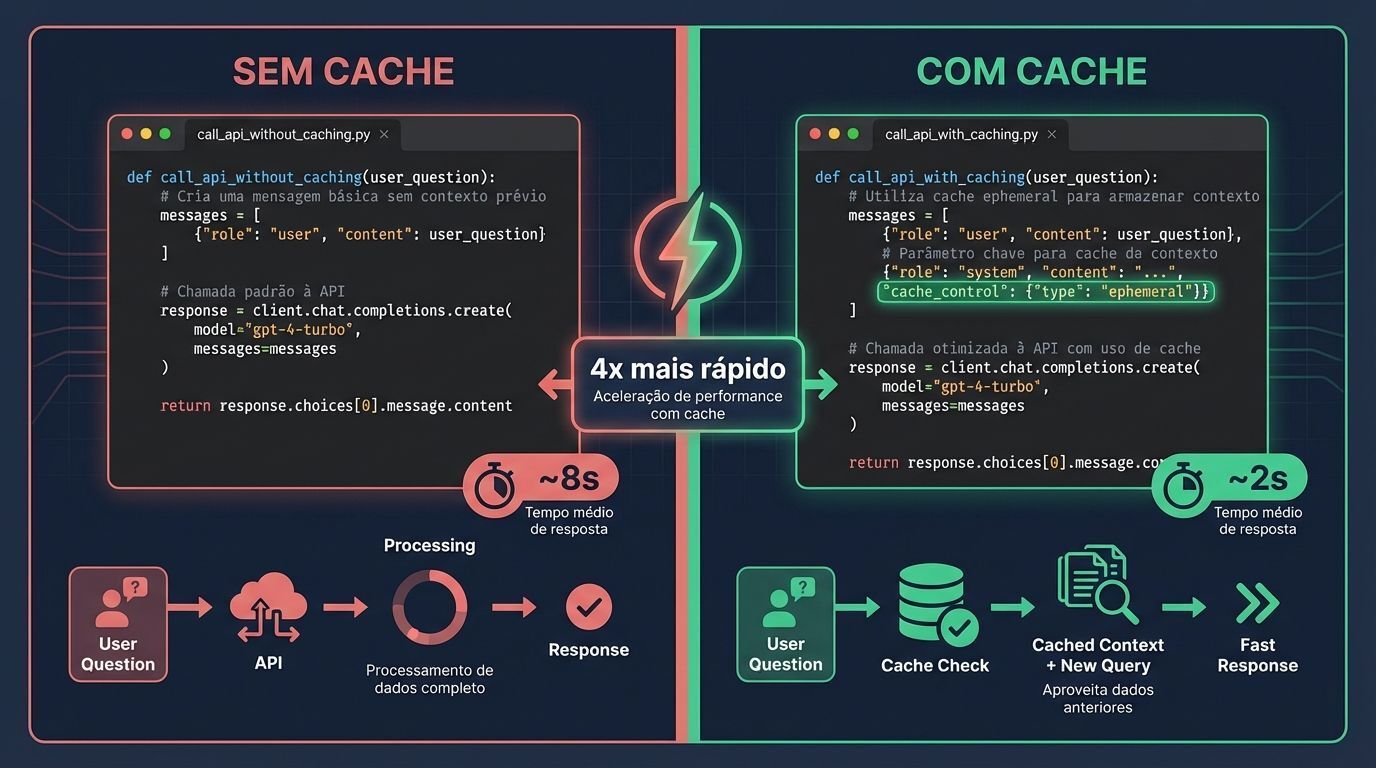
Implementação prática com código: tutorial completo
Vamos fazer um walkthrough implementando prompt caching para um caso de uso real de gestão de produto: criar um assistente de documentação de produto que pode responder perguntas sobre manuais técnicos extensos sem incorrer em custos repetidos.
Configuração do ambiente e integração de bibliotecas
Configurar seu ambiente para prompt caching requer várias ferramentas fundamentais. A API da Anthropic serve como sua porta de entrada para as capacidades do Claude, enquanto bibliotecas especializadas lidam com o trabalho pesado nos bastidores.
Vamos começar com os componentes essenciais:
import anthropic
import time
import requests
from bs4 import BeautifulSoup
Sua API key atua como sua credencial de acesso pessoal. Armazene-a com segurança usando variáveis de ambiente em vez de codificá-la diretamente em sua aplicação:
import os
import getpass
api_key = getpass.getpass("Digite sua API key da Anthropic: ")
os.environ['ANTHROPIC_API_KEY'] = api_key
from anthropic import Anthropic
client = Anthropic()
A seleção do modelo define seus parâmetros de interação. Para prompt caching com Anthropic, modelos mais novos como Claude 3.5 Sonnet fornecem performance otimizada:
MODEL_NAME = "claude-3-5-sonnet-20241022"
Configurando a API da Anthropic
Aqui estão os passos para configurar a API:
Vá para o Console da Anthropic em https://console.anthropic.com/
Faça login no console
Você será navegado para o dashboard
Clique em "Get API keys"
Clique em "Create Key" para gerar uma API
Selecione o workspace (recomendo default)
Defina o nome e clique em "Add" para gerar a API
Salve sua API key - você não poderá visualizá-la novamente
Após isso, você pode executar o comando client = Anthropic(), e ele automaticamente usará a variável de ambiente.

Buscando conteúdo para análise
O componente de recuperação de dados estabelece nossa base de testes. Usamos a biblioteca Requests para buscar conteúdo web e BeautifulSoup para transformar HTML bruto em texto utilizável:
def fetch_article_content(url):
headers = {'User-Agent': 'Mozilla/5.0...'} # Identificação do navegador
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.text, 'html.parser')
# Limpar o conteúdo
for script in soup(["script", "style"]):
script.extract()
# Extrair e formatar texto
article_content = soup.get_text()
lines = (line.strip() for line in article_content.splitlines())
article_content = '\n'.join(chunk for chunk in chunks if chunk)
return article_content
Detalhes de implementação: mecanismo e pseudocódigo
A implementação do prompt caching com a API da Anthropic envolve vários componentes estratégicos. O workflow fundamental envolve duas funções principais:
Chamada de API sem cache: Estabelece nossas métricas de performance baseline
Chamada de API com cache: Demonstra os ganhos de eficiência do caching
Aqui está como estruturamos essas funções:
def call_api_without_caching(article_content, user_question):
start_time = time.time()
message = client.messages.create(
model=MODEL_NAME,
max_tokens=1024,
system=[
{
"type": "text",
"text": "Você é um assistente útil que responde perguntas sobre documentos."
},
{
"type": "text",
"text": f"Documento:\n\n{article_content}"
}
],
messages=[
{"role": "user", "content": user_question}
]
)
elapsed_time = time.time() - start_time
return message, elapsed_time
def call_api_with_caching(article_content, user_question):
start_time = time.time()
message = client.messages.create(
model=MODEL_NAME,
max_tokens=1024,
system=[
{
"type": "text",
"text": "Você é um assistente útil que responde perguntas sobre documentos."
},
{
"type": "text",
"text": f"Documento:\n\n{article_content}",
"cache_control": {"type": "ephemeral"}
}
],
messages=[
{"role": "user", "content": user_question}
],
extra_headers={"anthropic-beta": "prompt-caching-2024-07-31"}
)
elapsed_time = time.time() - start_time
return message, elapsed_time
O mecanismo-chave de caching depende do parâmetro cache_control. Defini-lo como "ephemeral" instrui o sistema da Anthropic a fazer cache desse conteúdo. O cabeçalho beta especial "prompt-caching-2024-07-31" ativa o recurso de caching.
Abordagem de comparação de performance
Para demonstrar os benefícios do caching, nós:
Fazemos uma chamada inicial de API sem benefícios de caching
Esperamos um breve período (30 segundos no nosso exemplo)
Fazemos uma segunda chamada que se beneficia do conteúdo em cache
Comparamos métricas de performance entre as duas chamadas
A comparação de performance tipicamente mostra:
Tempo de resposta: Chamadas em cache são frequentemente 1.5-4x mais rápidas
Uso de tokens: Tokens de entrada drasticamente reduzidos para chamadas em cache
Consistência de output: Respostas similares apesar de diferentes caminhos de processamento

Melhores práticas, desafios e tendências futuras
Melhores práticas para prompt caching
Ao adicionar prompt caching ao seu produto, siga estas práticas-chave:
Estruture prompts estrategicamente: Coloque conteúdo estático no início. Adicione conteúdo dinâmico no final. Isso maximiza acertos de cache.
Monitore métricas de performance: Rastreie taxas de acerto de cache. Meça melhorias de tempo de resposta. Calcule economia de custos. Deixe esses números guiarem a otimização.
Crie instruções consistentes: Use formatação similar entre prompts. Isso ajuda o sistema a identificar padrões correspondentes.
Equilibre tamanho de cache com performance: Muito pequeno significa erros frequentes. Muito grande desperdiça recursos. Encontre seu ponto ideal.
Desafios comuns e soluções
O prompt caching não é isento de obstáculos. Aqui estão os principais:
Desafio | Solução |
|---|---|
Cache misses | Revise consistência de prompts. Ajuste limites de similaridade para permitir variações menores |
Invalidação de cache | Implemente keep-alive pings para aplicações críticas. Esses refrescam prompts importantes em cache |
Limitações de armazenamento | Use valores TTL (Time-to-Live) sabiamente. Priorize quais prompts merecem caching |
Preocupações de privacidade | Use criptografia para informações sensíveis. Implemente controles de acesso adequados |
Tendências emergentes
O futuro do prompt caching parece empolgante:
Semantic caching: Além de correspondência exata, sistemas entenderão o significado do prompt. Perguntas similares atingirão o mesmo cache.
Estratégias de caching personalizadas: Diferentes usuários precisam de diferentes abordagens de caching. Sistemas otimizarão baseados em padrões de uso.
Redes de cache distribuídas: Soluções enterprise compartilharão caches entre aplicações. Isso maximiza reutilização e economia.
Analytics de cache: Ferramentas avançadas ajudarão a identificar oportunidades de caching. Elas recomendarão estruturas de prompt para melhor performance.
O prompt caching ainda está evoluindo. O que vemos hoje é apenas o começo. À medida que os modelos crescem mais poderosos, o caching eficaz se torna ainda mais crucial. Não é apenas sobre economizar dinheiro — é sobre permitir experiências de produto totalmente novas que de outra forma seriam impossíveis.
Perguntas frequentes sobre prompt caching
Quanto tempo os prompts ficam em cache?
Os caches da Anthropic expiram após 5 minutos de inatividade, enquanto a implementação da OpenAI mantém prefixos em cache por 5-10 minutos (ocasionalmente até uma hora durante períodos de baixa demanda).
Prompt caching funciona com todos os modelos?
Não. Modelos mais recentes como Claude 3.5 Sonnet e versões específicas do GPT-4 suportam prompt caching. Verifique a documentação do seu provedor para compatibilidade.
Como estruturo meus prompts para melhor caching?
Coloque conteúdo estático (instruções, documentos, contexto) no início do prompt e conteúdo variável (perguntas do usuário, inputs dinâmicos) no final.
Prompt caching compromete a privacidade dos dados?
Os provedores implementam medidas de segurança, mas você deve criptografar informações sensíveis e implementar controles de acesso adequados para dados confidenciais.
Qual é o tamanho mínimo de prompt para caching valer a pena?
Geralmente, prompts com mais de 1.024 tokens se beneficiam significativamente do caching. Para prompts menores, o overhead pode superar os benefícios.
Conclusão
O prompt caching representa um avanço crucial no desenvolvimento de produtos de IA. Ao implementar estrategicamente essa técnica, equipes podem melhorar dramaticamente métricas de performance enquanto reduzem custos operacionais — transformando capacidades teóricas de IA em recursos práticos de produto.
A implementação requer estruturação cuidadosa de prompts, com conteúdo estático no início e conteúdo dinâmico no final. Embora desafios como cache misses e limitações de armazenamento existam, eles são gerenciáveis com estratégias adequadas de monitoramento e otimização.
Olhando para o futuro, tendências como semantic caching e estratégias de caching personalizadas vão aprimorar ainda mais essas capacidades. Para equipes de produto, o prompt caching não é apenas uma otimização técnica — é uma vantagem estratégica que permite experiências de produto e casos de uso totalmente novos.
À medida que a IA se torna cada vez mais central no desenvolvimento de produtos, técnicas como prompt caching separarão produtos de alta performance do resto. Comece a implementar essas abordagens agora para criar recursos de IA que sejam não apenas poderosos, mas também responsivos, cost-effective e deliciosos de usar.