- Data Hackers Newsletter
- Posts
- Prompt Caching: como diminuir seus custos de IA com OpenAI
Prompt Caching: como diminuir seus custos de IA com OpenAI
Entenda como reutilizar pedaços dos seus prompts pode reduzir o custo e a latência em suas aplicações de IA
Data Hackers
21 de fevereiro de 2026
O Prompt Caching é uma funcionalidade poderosa da OpenAI que pode reduzir significativamente tanto a latência quanto os custos das suas aplicações de IA. Com essa tecnologia, é possível alcançar reduções de até 80% na latência e até 90% nos custos de tokens de entrada. Melhor ainda: funciona automaticamente em todas as suas requisições de API, sem necessidade de alterações no código.
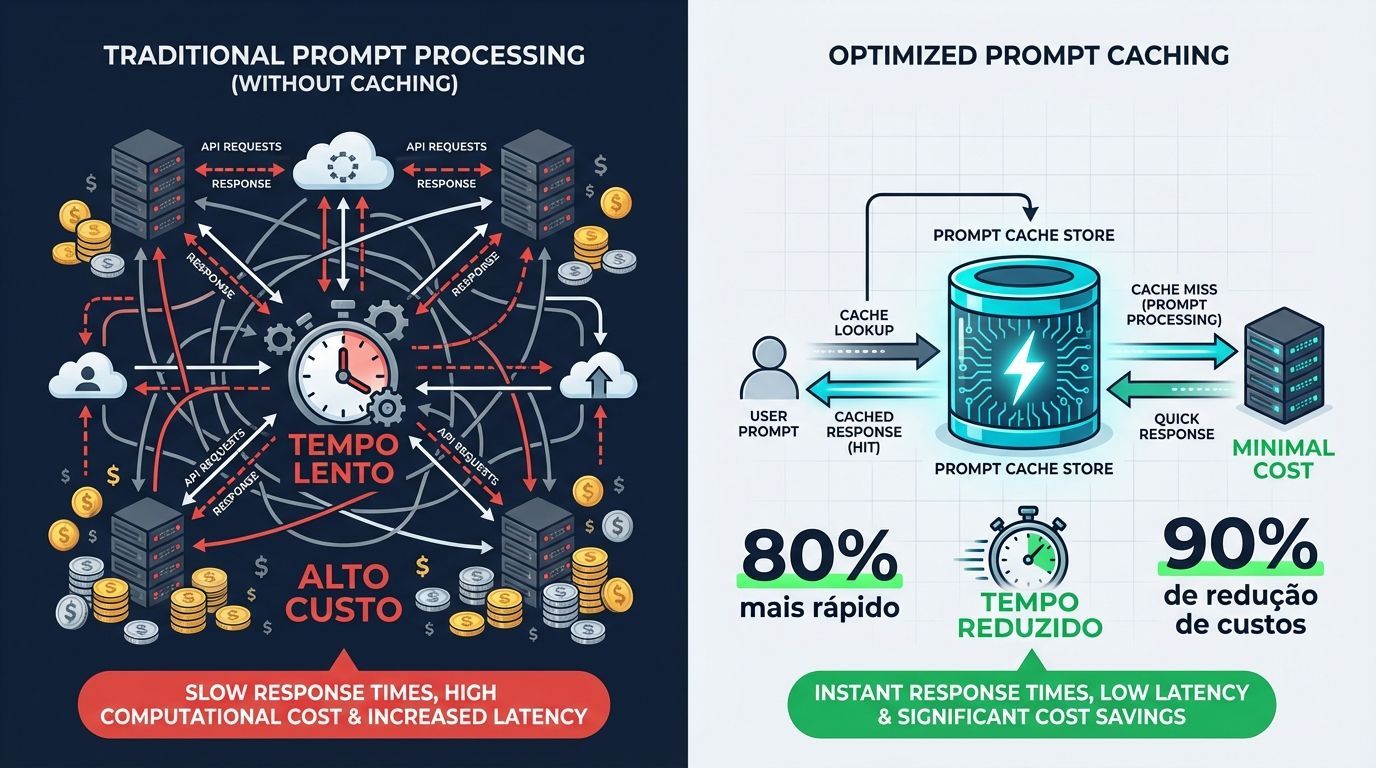
O que é Prompt Caching e como funciona
Muitos prompts de modelos contêm conteúdo repetitivo, como prompts de sistema e instruções comuns. O Prompt Caching funciona roteando requisições da API para servidores que processaram recentemente o mesmo prompt, tornando o processamento mais barato e rápido do que analisar um prompt do zero.
O recurso está habilitado para todos os modelos recentes da OpenAI, incluindo gpt-4o e versões mais novas. O melhor de tudo? Não há taxas adicionais associadas ao uso do Prompt Caching.
Como o sistema processa suas requisições
Quando você faz uma requisição à API, o seguinte processo ocorre:
Cache Routing: As requisições são roteadas para uma máquina baseada em um hash do prefixo inicial do prompt (normalmente os primeiros 256 tokens)
Cache Lookup: O sistema verifica se a porção inicial (prefixo) do seu prompt existe no cache da máquina selecionada
Cache Hit: Se um prefixo correspondente é encontrado, o sistema usa o resultado em cache, reduzindo drasticamente a latência e os custos
Cache Miss: Se nenhum prefixo correspondente é encontrado, o sistema processa seu prompt completo, armazenando o prefixo em cache para requisições futuras

Estruturando seus prompts para máximo aproveitamento
Para aproveitar ao máximo o Prompt Caching, a estrutura do seu prompt é fundamental. Cache hits são possíveis apenas para correspondências exatas de prefixo dentro de um prompt.
Boas práticas de estruturação
Posição no Prompt | Tipo de Conteúdo | Exemplo |
|---|---|---|
Início | Conteúdo estático (instruções, exemplos, contexto) | Prompts de sistema, guidelines, exemplos few-shot |
Meio | Ferramentas e schemas | Definições de tools, structured outputs |
Final | Conteúdo dinâmico e variável | Inputs específicos do usuário, dados contextuais |
Essa abordagem maximiza as chances de cache hits, pois o conteúdo que mais varia fica posicionado no final do prompt.
Políticas de retenção de cache
O Prompt Caching oferece duas políticas de retenção: in-memory e extended retention.
In-memory cache retention
Disponível para todos os modelos que suportam Prompt Caching:
Prefixos em cache permanecem ativos por 5 a 10 minutos de inatividade
Tempo máximo de retenção: até uma hora
Armazenamento apenas na memória volátil da GPU
Extended cache retention
Disponível para modelos específicos (gpt-5.2, gpt-5.1, gpt-5, gpt-4.1 e variantes codex):
Mantém prefixos em cache ativos por períodos mais longos
Tempo máximo de retenção: até 24 horas
Utiliza armazenamento local da GPU para tensores key/value

Para configurar a política de retenção, use o parâmetro prompt_cache_retention:
{
"model": "gpt-5.1",
"input": "Seu prompt aqui...",
"prompt_cache_retention": "24h"
}
Requisitos e monitoramento
Requisitos básicos
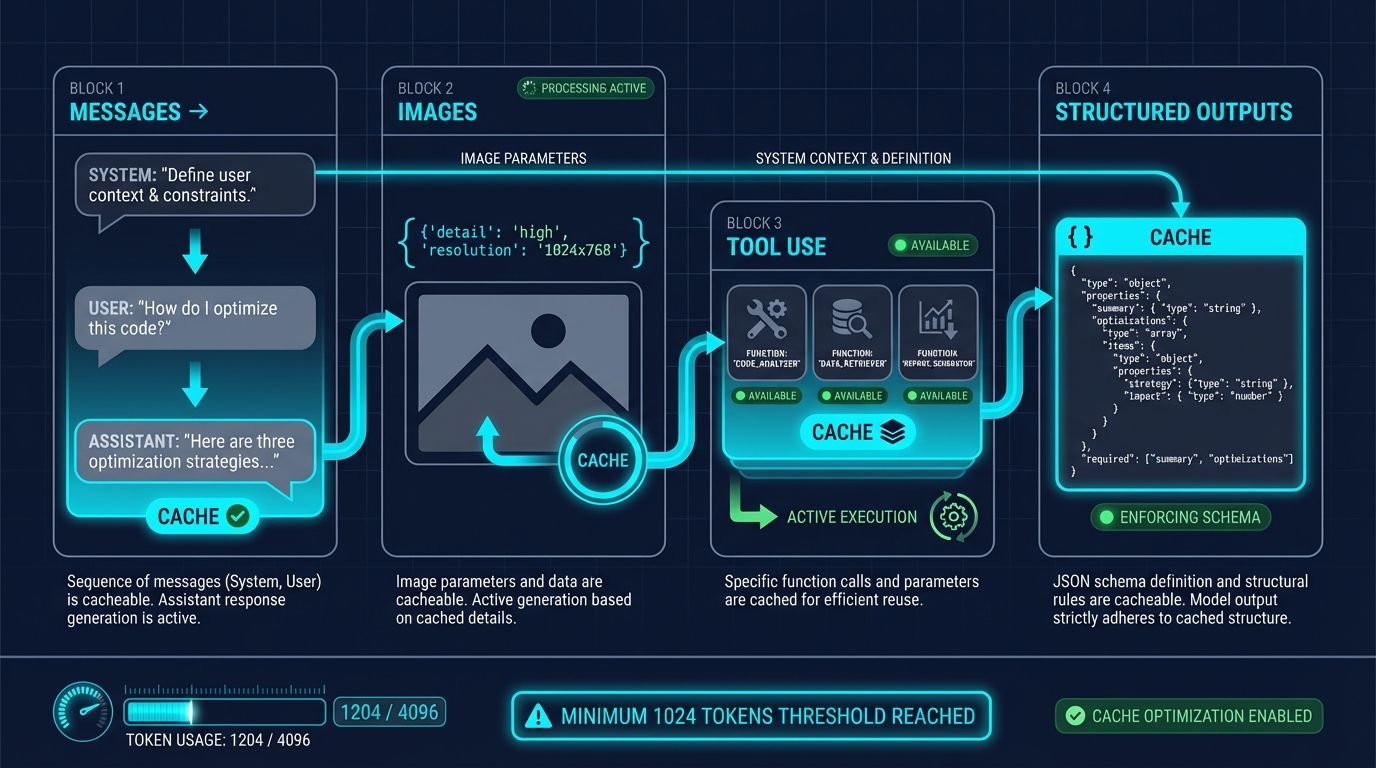
O caching está disponível para prompts contendo 1024 tokens ou mais
Todas as requisições exibirão um campo
cached_tokensindicando quantos tokens foram um cache hitPara requisições com menos de 1024 tokens,
cached_tokensserá zero
Exemplo de resposta com métricas de cache
"usage": {
"prompt_tokens": 2006,
"completion_tokens": 300,
"total_tokens": 2306,
"prompt_tokens_details": {
"cached_tokens": 1920
},
"completion_tokens_details": {
"reasoning_tokens": 0,
"accepted_prediction_tokens": 0,
"rejected_prediction_tokens": 0
}
}
O que pode ser cacheado
Messages: O array completo de mensagens, incluindo interações system, user e assistant
Images: Imagens incluídas em mensagens de usuário (links ou base64), desde que o parâmetro
detailseja idênticoTool use: Tanto o array de mensagens quanto a lista de
toolsdisponíveisStructured outputs: O schema de structured output serve como prefixo da mensagem do sistema
Estratégias para otimizar seu uso de cache
1. Use o parâmetro prompt_cache_key
O parâmetro prompt_cache_key permite influenciar o roteamento e melhorar as taxas de cache hit. Isso é especialmente benéfico quando muitas requisições compartilham prefixos longos e comuns.
Dica importante: Selecione uma granularidade que mantenha cada combinação única de prefixo-prompt_cache_key abaixo de 15 requisições por minuto para evitar overflow de cache.
2. Monitore suas métricas de performance
Acompanhe constantemente:
Taxas de cache hit
Latência das requisições
Proporção de tokens em cache
Você pode monitorar suas contagens de tokens em cache através dos logs do campo usage ou no dashboard de uso da OpenAI.
3. Mantenha um fluxo constante de requisições
Manter um stream constante de requisições com prefixos de prompt idênticos minimiza evictions de cache e maximiza os benefícios do caching.
Privacidade e segurança dos dados
Uma preocupação comum é sobre a privacidade dos dados armazenados em cache. Aqui estão os pontos principais:
Caches não são compartilhados entre organizações: Apenas membros da mesma organização podem acessar caches de prompts idênticos
Zero Data Retention: O in-memory cache retention é elegível para Zero Data Retention. Com extended caching, os tensores key/value podem ser mantidos no armazenamento local da GPU
Data Residency: O in-memory Prompt Caching é compatível com todas as regiões de Data Residency. Extended caching é compatível apenas com regiões que incluem Regional Inference

Perguntas frequentes
O Prompt Caching afeta a geração de tokens de saída ou a resposta final da API?
Não. O Prompt Caching não influencia a geração de tokens de saída ou a resposta final fornecida pela API. A resposta gerada será idêntica, independentemente do uso de cache, pois apenas o prompt é armazenado em cache.
Há alguma maneira de limpar o cache manualmente?
Atualmente, não há opção para limpeza manual do cache. Prompts que não foram utilizados recentemente são automaticamente removidos do cache após 5-10 minutos de inatividade.
Vou pagar extra pelo uso do Prompt Caching?
Não. O caching acontece automaticamente, sem necessidade de ação explícita ou custo extra para usar o recurso.
Prompts em cache contribuem para os limites de rate limit (TPM)?
Sim, o caching não afeta os rate limits.
Conclusão
O Prompt Caching é uma ferramenta essencial para desenvolvedores que buscam otimizar custos e performance em aplicações de IA. Com a estruturação adequada dos prompts e o uso inteligente das políticas de retenção, é possível alcançar economias significativas sem comprometer a qualidade das respostas.
A melhor parte é que, uma vez implementadas as boas práticas de estruturação de prompts, o sistema funciona automaticamente, permitindo que você se concentre no desenvolvimento de funcionalidades enquanto a OpenAI cuida da otimização de performance e custos.
Quer aprender mais sobre otimização de prompts e desenvolvimento com IA? Continue acompanhando o Data Hackers Blog para mais conteúdos técnicos e práticos sobre inteligência artificial e machine learning.