- Data Hackers Newsletter
- Posts
- Por que seu sistema de IA está falhando (e como o Router pode resolver isso)
Por que seu sistema de IA está falhando (e como o Router pode resolver isso)
Soluções que orquestram diferentes modelos de IA podem entregar resultados incríveis, mas é preciso planejar e ter uma série de cuidados
Data Hackers
5 de fevereiro de 2026
Nos últimos dois anos, a indústria de IA tem estado travada em uma corrida para construir modelos de linguagem cada vez maiores. GPT-4, Claude, Gemini: cada um prometendo ser a solução singular para todos os problemas de IA. Mas enquanto empresas competiam para criar o maior cérebro artificial, uma revolução silenciosa estava acontecendo em ambientes de produção. Desenvolvedores pararam de perguntar "qual modelo é o melhor?" e começaram a perguntar "como faço múltiplos modelos trabalharem juntos?"
Esta mudança marca a ascensão da orquestração de IA, e está transformando como construímos aplicações inteligentes.
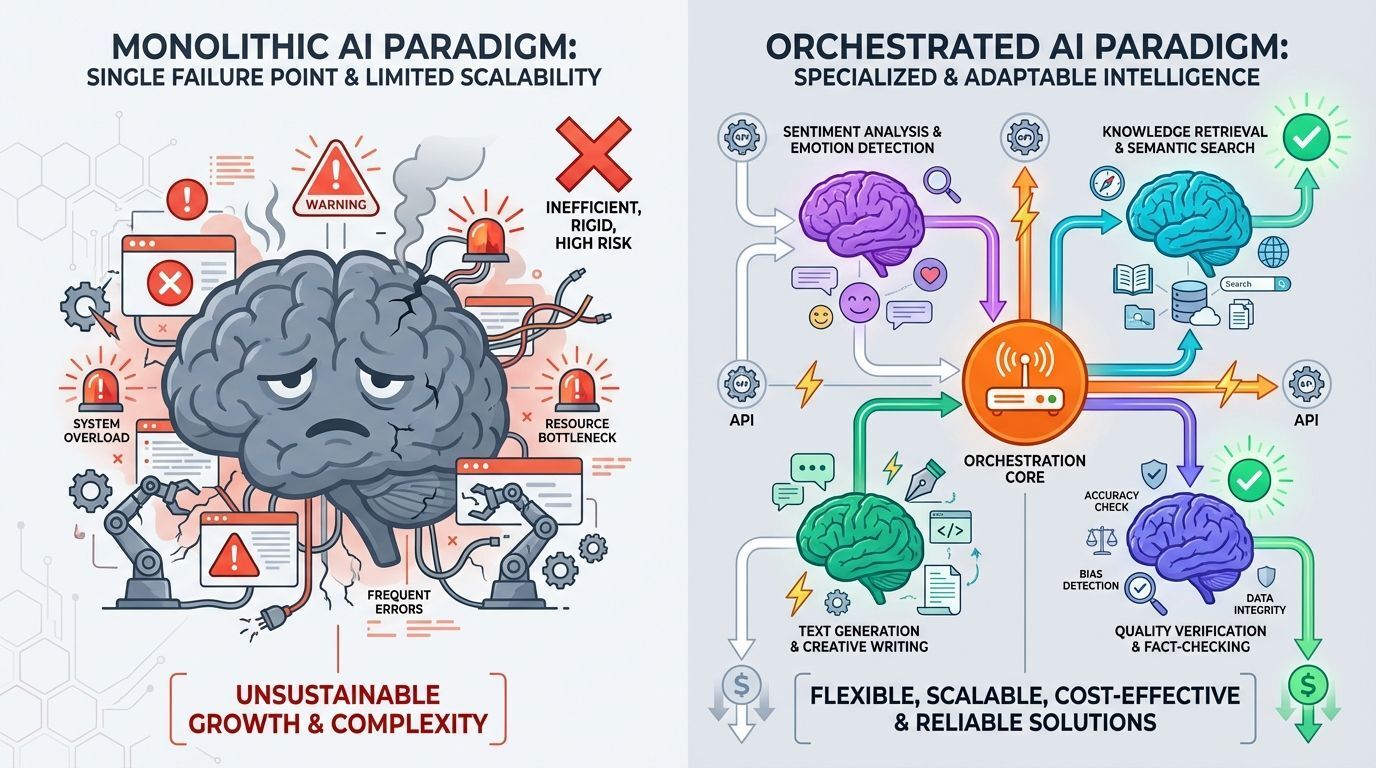
Por que uma única IA não pode dominar tudo
O sonho de um único modelo de IA todo-poderoso é atraente. Uma chamada de API, uma resposta, uma conta. Mas a realidade tem se mostrado mais complexa.
Considere uma aplicação de atendimento ao cliente. Você precisa de análise de sentimento para avaliar a emoção do cliente, recuperação de conhecimento para encontrar informações relevantes, geração de resposta para criar respostas e verificação de qualidade para garantir precisão. Embora o GPT-4 possa tecnicamente lidar com todas essas tarefas, cada uma requer otimização diferente. Um modelo treinado para se destacar em análise de sentimento faz diferentes trade-offs arquiteturais do que um otimizado para geração de texto.
O avanço não está em construir um modelo para dominar todos. Está em coordenar múltiplos especialistas.
Isso espelha um padrão que já vimos antes na arquitetura de software. Microserviços substituíram aplicações monolíticas não porque qualquer microserviço individual fosse superior, mas porque serviços especializados coordenados provaram ser mais sustentáveis, escaláveis e eficazes. A IA está tendo seu momento de microserviços.
A stack de três camadas
Entender aplicações modernas de IA requer pensar em camadas. A arquitetura que emergiu de deployments em produção parece notavelmente consistente.
Model Layer (camada de modelos)
A Model Layer fica na fundação. Isso inclui seus LLMs, seja GPT-4, Claude, modelos locais como Llama, ou modelos especializados para visão, código ou análise. Cada modelo traz capacidades específicas: raciocínio, geração, classificação ou transformação. O insight chave é que você não está mais escolhendo um modelo. Você está compondo uma coleção.
Tool Layer (camada de ferramentas)
A Tool Layer permite ação. Modelos de linguagem podem pensar, mas não conseguem fazer nada sozinhos. Eles precisam de ferramentas para interagir com o mundo. Esta camada inclui busca na web, consultas a bancos de dados, chamadas de API, ambientes de execução de código e sistemas de arquivos. Quando o Claude "busca na web" ou o ChatGPT "executa código Python", eles estão usando ferramentas desta camada. O Model Context Protocol (MCP), recentemente lançado pela Anthropic, está padronizando como modelos se conectam a ferramentas, tornando esta camada cada vez mais plug-and-play.
Orchestration Layer (camada de orquestração)
A Orchestration Layer coordena tudo. É aqui que a inteligência do seu sistema realmente vive. O orquestrador decide qual modelo invocar para qual tarefa, quando chamar ferramentas, como encadear operações juntas e como lidar com falhas. É o maestro da sua sinfonia de IA.
Modelos são músicos, ferramentas são instrumentos, e orquestração é a partitura que diz a todos quando tocar.

Frameworks de orquestração: entendendo os padrões
Assim como React e Vue padronizaram o desenvolvimento frontend, frameworks de orquestração estão padronizando como construímos sistemas de IA. Mas antes de discutirmos ferramentas específicas, precisamos entender os padrões arquiteturais que eles representam. Ferramentas vêm e vão. Padrões perduram.
Chain Pattern (lógica sequencial)
O Chain Pattern é o padrão mais básico de orquestração. Pense nele como um pipeline de dados onde a saída de cada etapa se torna a entrada da próxima etapa. Pergunta do usuário → recuperar contexto → gerar resposta → validar saída. Cada operação acontece em sequência, com o orquestrador gerenciando as transições. O LangChain foi pioneiro neste padrão e construiu um framework inteiro em torno de tornar chains composáveis e reutilizáveis.
A força das chains está em sua simplicidade: você pode raciocinar sobre o fluxo, fazer debug passo a passo e otimizar estágios individuais. A limitação é a rigidez. Chains não se adaptam com base em resultados intermediários. Se a etapa dois descobre que a pergunta não pode ser respondida, a chain ainda marcha pelas etapas três e quatro. Mas para workflows previsíveis com estágios claros, chains funcionam bem.
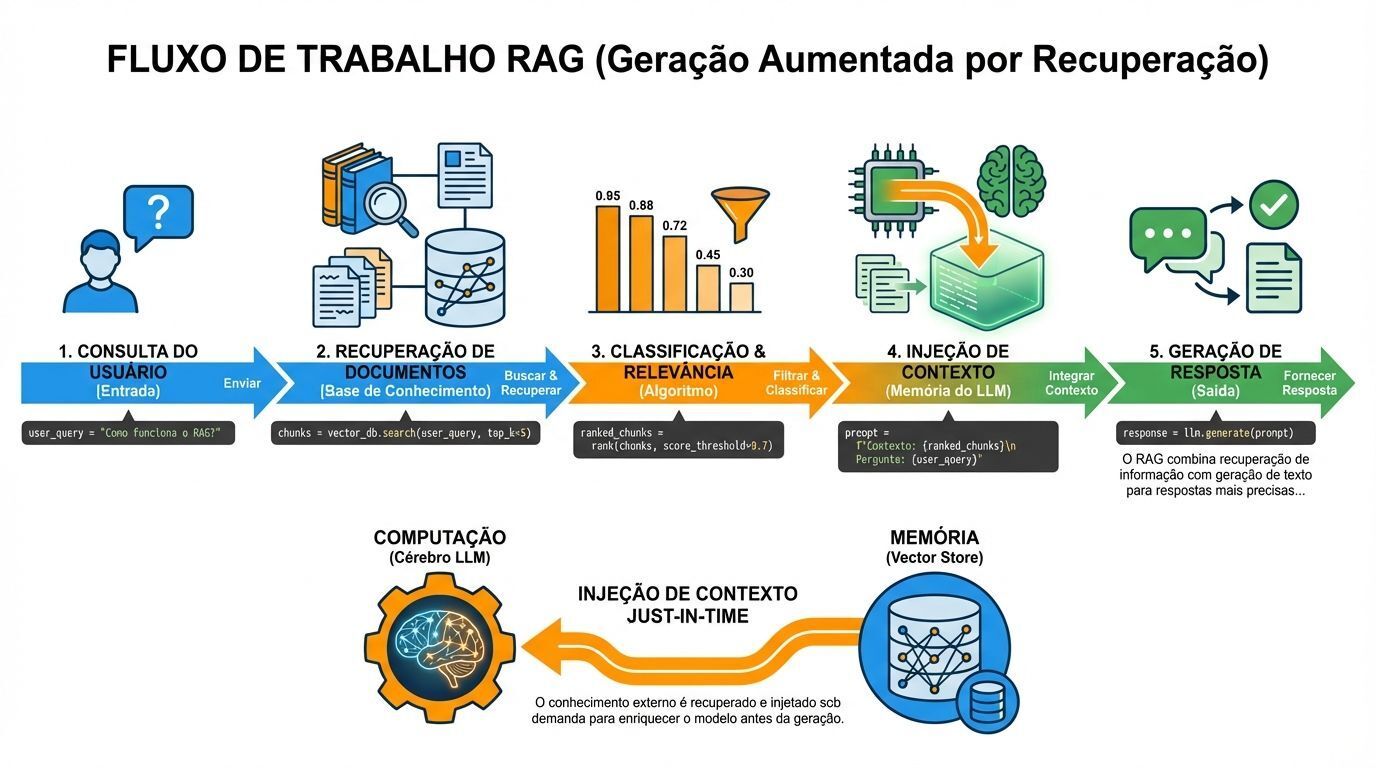
RAG Pattern (lógica de recuperação primeiro)
O RAG Pattern (Retrieval-Augmented Generation) emergiu de um problema específico: modelos de linguagem alucinam quando não têm informação. A solução é simples: recupere informações relevantes primeiro, depois gere respostas fundamentadas nesses dados.
Mas arquiteturalmente, RAG representa algo mais profundo: Injeção de Contexto Just-in-Time. Pense nisso como a separação de Computação (o LLM) da Memória (o Vector Store). O modelo em si permanece estático. Ele não aprende novos fatos. Em vez disso, você troca o que está na "RAM" do modelo injetando contexto relevante em sua janela de prompt. Você não está retreinando o cérebro. Você está dando acesso às informações exatas que ele precisa, precisamente quando precisa.
Este princípio arquitetural funciona porque transforma um problema generativo em um problema de recuperação mais síntese, e recuperação é mais confiável que geração.
O fluxo típico inclui:
Etapa | Ação |
|---|---|
1 | Query (consulta do usuário) |
2 | Buscar base de conhecimento |
3 | Ranquear resultados por relevância |
4 | Injetar no contexto |
5 | Gerar resposta |
O LlamaIndex construiu seu framework inteiro em torno de otimizar este padrão, lidando com as partes difíceis de chunking de documentos, geração de embeddings, armazenamento vetorial e ranking de recuperação.
Multi-Agent Pattern (lógica de delegação)
O Multi-Agent Pattern representa a evolução mais sofisticada da orquestração. Em vez de um fluxo sequencial ou uma etapa de recuperação, você cria agentes especializados que delegam uns aos outros. Um agente "planejador" quebra tarefas complexas. Agentes "pesquisadores" coletam informação. Agentes "analistas" processam dados. Agentes "escritores" produzem output. Agentes "críticos" revisam qualidade.
O CrewAI exemplifica este padrão, mas o conceito precede a ferramenta. O insight arquitetural é que inteligência complexa emerge da coordenação entre especialistas, não de um generalista tentando fazer tudo. Cada agente tem uma responsabilidade estreita, critérios claros de sucesso e a habilidade de pedir ajuda a outros agentes.
A escolha entre padrões não é sobre qual é "melhor". É sobre combinar padrão com problema:
Workflows simples e previsíveis? Use chains.
Aplicações intensivas em conhecimento? Use RAG.
Raciocínio complexo de múltiplas etapas? Use multi-agent.
Sistemas de produção frequentemente combinam todos os três: um sistema multi-agente onde cada agente usa RAG internamente e se comunica através de chains.
Do prompt ao pipeline: o Router muda tudo
Entender orquestração conceitualmente é uma coisa. Vê-la em produção revela por que ela importa e expõe o componente que determina sucesso ou falha.
Considere um assistente de codificação que ajuda desenvolvedores a debugar problemas. Uma abordagem de modelo único enviaria código e mensagens de erro para o GPT-4 e esperaria pelo melhor. Um sistema orquestrado funciona diferentemente, e seu sucesso depende de um componente crítico: o Router.
O Router é o motor de tomada de decisão no coração de todo sistema orquestrado. Ele examina requisições recebidas e determina qual caminho através do seu sistema elas devem tomar. Isso não é apenas encanamento. A precisão do roteamento determina se seu sistema orquestrado supera um modelo único ou desperdiça tempo e dinheiro em complexidade desnecessária.
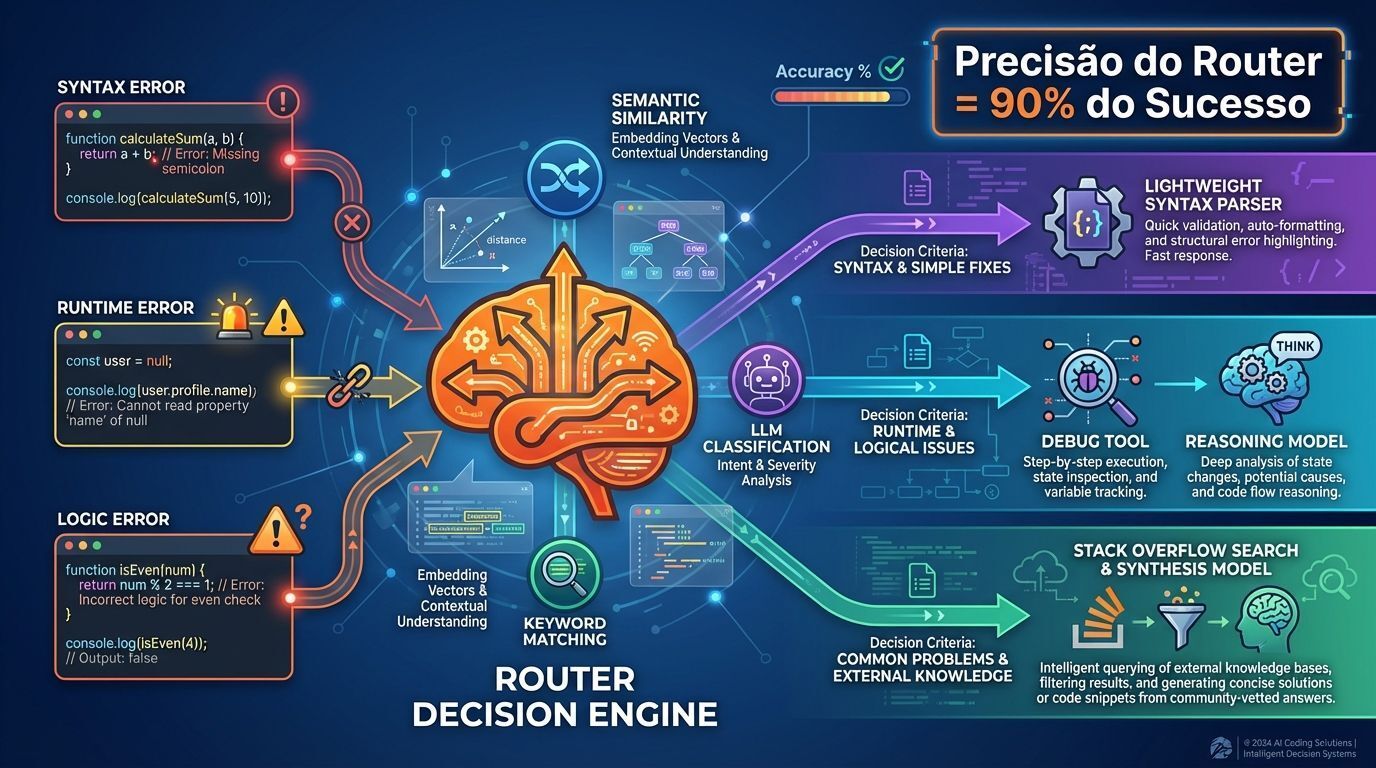
Quando um desenvolvedor submete um problema, o Router deve decidir: É um erro de sintaxe? Um erro de runtime? Um erro de lógica? Cada tipo requer tratamento diferente:
Erros de sintaxe são roteados para um analisador de código especializado, um modelo leve fine-tuned para parsing de violações
Erros de runtime acionam a ferramenta de debug para examinar estado do programa, depois passam descobertas para um modelo de raciocínio que entende contexto de execução
Erros de lógica requerem um caminho completamente diferente: buscar Stack Overflow por problemas similares, recuperar contexto relevante, então invocar um modelo de raciocínio para sintetizar soluções
Como o Router decide?
Três abordagens dominam sistemas de produção:
1. Roteamento semântico: Usa similaridade de embeddings. Converte a pergunta do usuário em um vetor, compara com embeddings de perguntas exemplo para cada rota, e envia pelo caminho com maior similaridade. Rápido e efetivo para categorias claramente distintas.
2. Roteamento por palavras-chave: Examina sinais explícitos. Se a mensagem de erro contém "SyntaxError", roteia para o parser. Se contém "NullPointerException", roteia para o handler de runtime. Simples, rápido e surpreendentemente sólido quando você tem indicadores confiáveis.
3. Roteamento por decisão LLM: Usa um modelo pequeno e rápido como o Router em si. Envia a requisição para um modelo de classificação especializado que foi treinado ou prompteado para fazer decisões de roteamento. Mais flexível que palavras-chave, mais confiável que similaridade semântica pura, mas adiciona latência e custo.
O insight que realmente importa
O sucesso do seu sistema orquestrado depende 90% da precisão do Router, não da sofisticação dos seus modelos downstream. Uma resposta perfeita do GPT-4 enviada pelo caminho errado não ajuda ninguém. Uma resposta decente de um modelo especializado roteado corretamente resolve o problema.
Isso cria um target de otimização inesperado. Times obcecam sobre qual LLM usar para geração mas negligenciam a engenharia do Router. Eles deveriam fazer o oposto. Um Router simples fazendo decisões corretas supera um Router complexo que está frequentemente errado. Times de produção medem precisão de roteamento religiosamente. É a métrica que prevê o sucesso do sistema.
Quando orquestrar, quando manter simples
Nem toda aplicação de IA precisa de orquestração. Um chatbot que responde FAQs? Modelo único. Um sistema que classifica tickets de suporte? Modelo único. Gerando descrições de produtos? Modelo único.
Orquestração faz sentido quando você precisa de:
Múltiplas capacidades que nenhum modelo único trata bem
Dados externos ou ações (se sua IA precisa buscar bancos de dados, chamar APIs, ou executar código)
Confiabilidade através de redundância (sistemas de produção frequentemente encadeiam um modelo rápido e barato para processamento inicial com um modelo capaz e caro para casos complexos)
Otimização de custos (usar GPT-4 para tudo é caro; orquestração permite rotear tarefas simples para modelos mais baratos)
O framework de decisão é direto: comece simples. Use um modelo único até atingir limitações claras. Adicione orquestração quando a complexidade se pagar em melhores resultados, custos menores ou novas capacidades.
Considerações finais
A orquestração de IA representa uma maturação do campo. Estamos nos movendo de "qual modelo devo usar?" para "como devo arquitetar meu sistema de IA?" Isso espelha a evolução de toda tecnologia, de monolítico para distribuído, de escolher a melhor ferramenta para compor as ferramentas certas.
Os frameworks existem. Os padrões estão emergindo. A questão agora é se você vai construir aplicações de IA do jeito antigo (esperando que um modelo possa fazer tudo) ou do jeito novo: orquestrando modelos especializados e ferramentas em sistemas que são maiores que a soma de suas partes.
O futuro da IA não está em encontrar o modelo perfeito. Está em aprender a reger a orquestra.
FAQ sobre AI Orchestration
O que é orquestração de IA?
Orquestração de IA é a coordenação de múltiplos modelos especializados e ferramentas em um sistema unificado, onde cada componente executa tarefas específicas de forma otimizada.
Qual a diferença entre RAG e orquestração?
RAG (Retrieval-Augmented Generation) é um padrão específico de orquestração focado em recuperação de conhecimento. Orquestração é o conceito mais amplo de coordenar múltiplos componentes de IA.
Quando devo usar orquestração em vez de um único modelo?
Use orquestração quando precisar de múltiplas capacidades especializadas, integração com dados externos, redundância para confiabilidade ou otimização de custos através de roteamento inteligente.
Quais são os principais frameworks de orquestração?
Os principais são LangChain (para chains), LlamaIndex (para RAG) e CrewAI (para sistemas multi-agentes), além do Model Context Protocol como padrão emergente.
Como medir o sucesso de um sistema orquestrado?
A métrica mais importante é a precisão do Router. Um Router preciso que direciona requisições corretamente é mais valioso que modelos sofisticados mal roteados.