- Data Hackers Newsletter
- Posts
- De 25 para 3.000 tokens por segundo: a revolução dos provedores de LLM API que você precisa conhecer
De 25 para 3.000 tokens por segundo: a revolução dos provedores de LLM API que você precisa conhecer
Entenda como o design de hardware especializado e a otimização de software permitiram dar um salto absurdo na velocidade de inferência
Data Hackers
21 de fevereiro de 2026
Quando o GPT-4 foi lançado, suas respostas chegavam a uma velocidade média de 25 tokens por segundo. Para muitos desenvolvedores, essa latência era aceitável, mas definitivamente não era ideal para aplicações em tempo real. Então veio a Groq, com sua arquitetura customizada chamada Language Processing Unit (LPU), e tudo mudou. De repente, estávamos falando de 150 tokens por segundo — uma velocidade que transformou completamente as expectativas sobre o que era possível em termos de inferência de IA.
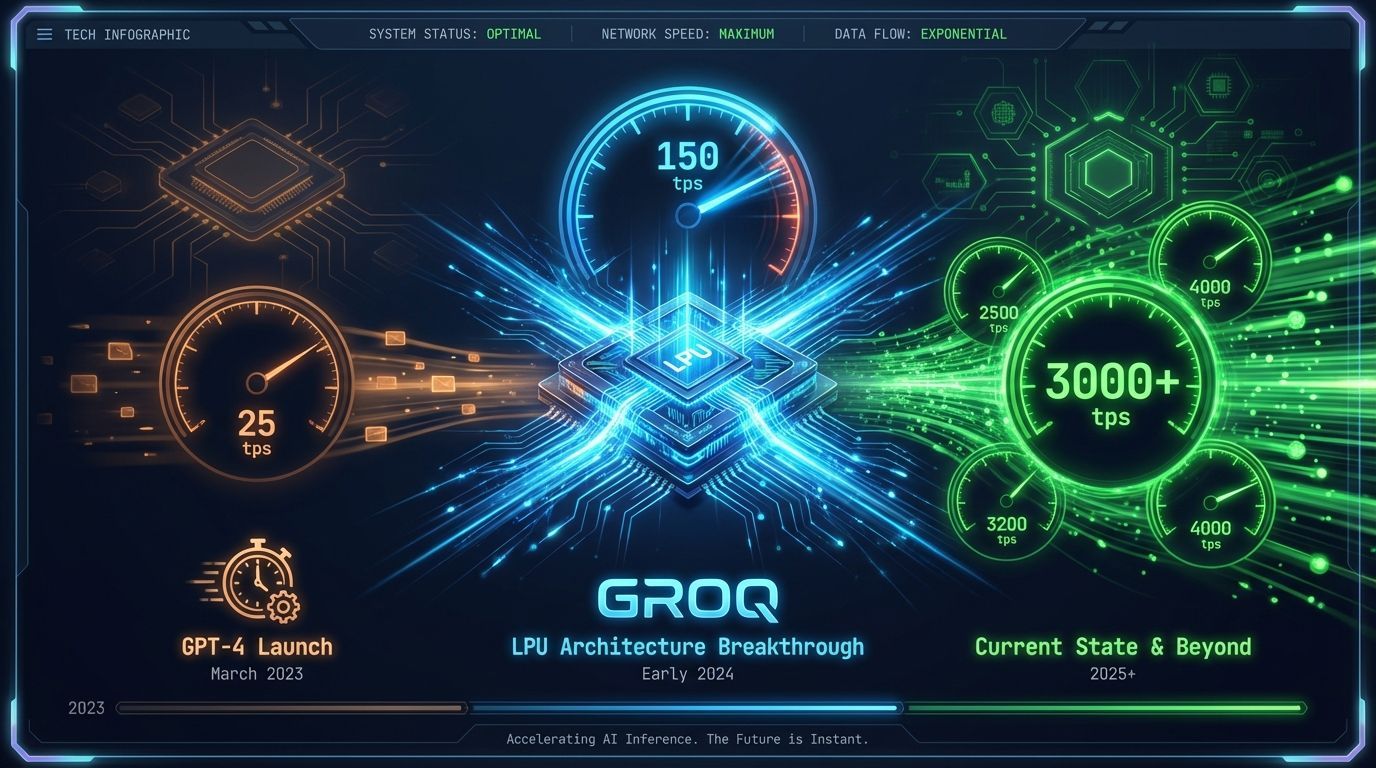
Mas a história não parou por aí. Hoje, alguns provedores já entregam milhares de tokens por segundo em modelos open source, provando que a velocidade de inferência não depende apenas de empilhar mais GPUs. O design de hardware especializado e a otimização de software fizeram toda a diferença.
Neste artigo, vamos explorar os 5 principais provedores de LLM API ultrarrápidas que estão definindo os novos padrões de performance. Vamos focar em latência, throughput e desempenho real em modelos open source populares — porque números em benchmarks são importantes, mas o que realmente importa é como esses sistemas se comportam em produção.
Por que a velocidade de inferência importa tanto?
Antes de mergulharmos nos provedores, vale entender por que a velocidade se tornou um fator tão crítico:
Experiência do usuário: aplicações de chat, assistentes virtuais e copilots precisam de respostas instantâneas
Viabilidade econômica: maior throughput significa processar mais requisições com a mesma infraestrutura
Casos de uso em tempo real: sistemas de análise de dados, processamento de streams e agentes autônomos dependem de latência mínima
Aplicações SaaS em produção: quando você cobra por uso, cada milissegundo de latência afeta diretamente seus custos operacionais

1. Cerebras: quando throughput extremo é prioridade
Cerebras adota uma abordagem radicalmente diferente ao usar um único chip de tamanho de wafer em vez de clusters de GPUs. Essa arquitetura elimina gargalos de comunicação entre chips e permite computação paralela massiva com altíssima largura de banda de memória.
Performance em números
3.115 tokens/segundo no gpt-oss-120B (high) com ~0,28s para o primeiro token
2.782 tokens/segundo no gpt-oss-120B (low) com ~0,29s para o primeiro token
1.669 tokens/segundo no GLM-4.7 com ~0,24s para o primeiro token
2.041 tokens/segundo no Llama 3.3 70B com ~0,31s para o primeiro token
Quando usar Cerebras
O Cerebras brilha em cenários onde throughput é mais importante que custo:
Endpoints de alta QPS (queries por segundo)
Geração de resumos longos
Extração de dados em larga escala
Geração de código complexa
Ponto de atenção: em alguns modelos, como o GLM-4.7, o custo pode ser mais alto que outros provedores. Avalie se o ganho de performance justifica o investimento para seu caso de uso específico.

2. Groq: a sensação de velocidade que importa
Se o Cerebras impressiona pelos números brutos, Groq conquistou desenvolvedores pela responsividade percebida. Sua LPU foi projetada para execução determinística, evitando overhead de scheduling comum em sistemas baseados em GPU. O resultado? Respostas que começam a aparecer quase instantaneamente.
Performance em números
935 tokens/segundo no gpt-oss-20B (high) com ~0,17s para o primeiro token
914 tokens/segundo no gpt-oss-20B (low) com ~0,17s para o primeiro token
467 tokens/segundo no gpt-oss-120B (high) com ~0,17s para o primeiro token
346 tokens/segundo no Llama 3.3 70B com ~0,19s para o primeiro token
Quando usar Groq
Groq é ideal para aplicações onde latência inicial é crítica:
Aplicações de chat e chatbots
Agentes conversacionais
Copilots de programação
Sistemas de resposta em tempo real
Mesmo quando outros provedores oferecem maior throughput de pico, o Groq consistentemente entrega uma experiência mais fluida e responsiva para o usuário final.
3. SambaNova: performance estável para a família Llama
SambaNova usa uma arquitetura de Dataflow Reconfigurável que processa modelos grandes de forma eficiente sem depender de scheduling tradicional de GPU. O sistema transmite dados pelo modelo de forma previsível, reduzindo overhead e melhorando throughput sustentado.

Performance em números
689 tokens/segundo no Llama 4 Maverick com ~0,80s para o primeiro token
611 tokens/segundo no gpt-oss-120B (high) com ~0,46s para o primeiro token
608 tokens/segundo no gpt-oss-120B (low) com ~0,76s para o primeiro token
365 tokens/segundo no Llama 3.3 70B com ~0,44s para o primeiro token
Quando usar SambaNova
É uma escolha sólida para equipes que:
Trabalham principalmente com modelos da família Llama
Precisam de alta performance consistente
Não querem otimizar apenas para números de benchmark isolados
4. Fireworks AI: consistência cross-model
Fireworks AI foca em otimização de software em vez de depender de vantagens de hardware específicas. A plataforma aplica técnicas como quantização, caching e ajustes específicos por modelo para extrair performance máxima. Também usa métodos avançados como speculative decoding para aumentar throughput sem prejudicar latência.
Performance em números
851 tokens/segundo no gpt-oss-120B (low) com ~0,30s para o primeiro token
791 tokens/segundo no gpt-oss-120B (high) com ~0,30s para o primeiro token
422 tokens/segundo no GLM-4.7 com ~0,47s para o primeiro token
359 tokens/segundo no GLM-4.7 non-reasoning com ~0,45s para o primeiro token
Quando usar Fireworks AI
Fireworks é ideal para equipes que:
Precisam rodar múltiplas famílias de modelos
Buscam performance consistente em produção
Querem uma solução "all-around" confiável

5. Baseten: especialista em GLM-4.7
Baseten se destaca particularmente no GLM-4.7, onde entrega performance próxima aos líderes de mercado. A plataforma foca em serving otimizado de modelos, utilização eficiente de GPU e fine-tuning cuidadoso para famílias específicas de modelos.
Performance em números
385 tokens/segundo no GLM-4.7 com ~0,59s para o primeiro token
369 tokens/segundo no GLM-4.7 non-reasoning com ~0,69s para o primeiro token
242 tokens/segundo no gpt-oss-120B (high)
246 tokens/segundo no gpt-oss-120B (low)
Quando usar Baseten
Se você está trabalhando com GLM-4.7, Baseten merece atenção especial. Nos dados disponíveis, fica logo atrás do Fireworks nesse modelo e bem à frente de muitos outros provedores.
Comparativo: qual provedor escolher?
Provedor | Força Principal | Throughput Máximo | Tempo até Primeiro Token | Melhor Caso de Uso |
|---|---|---|---|---|
Cerebras | Throughput extremo em modelos grandes | Até 3.115 TPS | ~0,24–0,31s | Endpoints de alta QPS, gerações longas |
Groq | Respostas mais rápidas percebidas | Até 935 TPS | ~0,16–0,19s | Chat interativo, agentes, copilots |
SambaNova | Alto throughput para família Llama | Até 689 TPS | ~0,44–0,80s | Deployments focados em Llama |
Fireworks | Velocidade consistente cross-model | Até 851 TPS | ~0,30–0,47s | Múltiplas famílias de modelos em produção |
Baseten | Performance forte em GLM-4.7 | Até 385 TPS | ~0,59–0,69s | Deployments focados em GLM |

FAQ: perguntas frequentes sobre provedores de LLM API
O que é TPS (tokens por segundo)?
TPS mede quantos tokens o modelo consegue gerar por segundo durante a inferência. Quanto maior o TPS, mais rápida é a geração de respostas longas.
Por que o tempo até o primeiro token importa?
O "time to first token" (TTFT) determina quanto tempo o usuário espera até começar a ver a resposta. Em aplicações interativas, TTFT baixo é crucial para a experiência do usuário.
Qual provedor é mais barato?
O custo varia por modelo e volume de uso. Cerebras pode ser mais caro em alguns modelos, mas o throughput extremo pode compensar em aplicações de alta escala. Sempre calcule o custo total de operação considerando throughput e latência.
Posso usar esses provedores para fine-tuning?
Alguns provedores oferecem fine-tuning, mas o foco deste artigo é em inferência. Verifique a documentação de cada provedor para opções de customização de modelos.
Como escolher entre throughput e latência inicial?
Depende do seu caso de uso:
Para chat e interação em tempo real: priorize latência inicial baixa (Groq)
Para processamento em lote e alta escala: priorize throughput (Cerebras)
Para uso geral: busque equilíbrio (Fireworks, SambaNova)
Conclusão: a nova era da inferência ultrarrápida
A evolução dos provedores de LLM API nos últimos anos mudou completamente o que consideramos "rápido" em IA. Saímos de 25 tokens por segundo para velocidades que ultrapassam 3.000 tokens por segundo em alguns cenários — um aumento de mais de 100x.
Essa revolução não foi apenas sobre hardware mais potente, mas sobre arquiteturas especializadas (Groq, Cerebras), otimização inteligente de software (Fireworks) e fine-tuning específico por modelo (SambaNova, Baseten).
Para desenvolvedores e empresas, isso significa:
Aplicações em tempo real são finalmente viáveis em larga escala
Custos operacionais podem ser drasticamente reduzidos com escolhas inteligentes de provedor
Experiência do usuário em aplicações de IA alcançou um novo patamar
A escolha do provedor ideal depende do seu caso de uso específico. Avalie não apenas o custo por token, mas o custo total de operação considerando throughput, latência e requisitos de escala.
O futuro da inferência de LLM é ultrarrápido — e está disponível agora.