- Data Hackers Newsletter
- Posts
- Context rot: como o aumento de tokens degrada a performance de LLMs
Context rot: como o aumento de tokens degrada a performance de LLMs
Entenda porque há uma degradação progressiva da performance dos LLMs à medida que a quantidade de tokens de entrada aumenta
Data Hackers
21 de fevereiro de 2026

Você provavelmente já ouviu falar sobre as janelas de contexto cada vez maiores nos lançamentos de novos modelos de linguagem. O Gemini e o GPT mais recentes suportam até 1 milhão de tokens, enquanto o Llama 4 impressiona com suporte para até 10 milhões de tokens. Para ter uma perspectiva, quatro livros combinados representam aproximadamente 1 milhão de tokens — provavelmente mais do que você imaginava.
Com modelos alcançando scores quase perfeitos no conhecido benchmark "needle in a haystack" (agulha no palheiro), é natural assumir que eles podem lidar de forma confiável com qualquer input longo para qualquer tarefa. Mas há uma razão importante pela qual os modelos se saem tão bem nesse teste específico — e ela revela uma limitação crítica que estamos chamando de context rot (deterioração de contexto).
O que é context rot e por que você deveria se preocupar
Context rot refere-se à degradação progressiva da performance de large language models (LLMs) conforme a quantidade de tokens de entrada aumenta. Mesmo que os modelos tecnicamente "suportem" milhões de tokens, isso não significa que eles processem toda essa informação de forma eficaz.
Pesquisas recentes da Chroma demonstram que modelos lutam conforme o comprimento da entrada aumenta, mesmo em tarefas que executam perfeitamente bem com inputs mais curtos. Esse fenômeno tem implicações diretas para quem está desenvolvendo aplicações de IA, especialmente chatbots com memória, sistemas de RAG (Retrieval-Augmented Generation) e assistentes conversacionais.
Por que o benchmark "needle in a haystack" não conta toda a história

O teste "needle in a haystack" é essencialmente uma tarefa de identificação simples: um fato aleatório é colocado no meio de um documento longo, e o modelo precisa identificá-lo. O problema? Essa tarefa frequentemente é projetada com correspondências lexicais diretas entre a pergunta e a "agulha".
Por exemplo:
Pergunta: "Qual foi o melhor conselho sobre corrida que recebi do meu colega de faculdade?"
Agulha: "O melhor conselho sobre corrida que recebi do meu colega de faculdade foi correr toda semana."
Nesse cenário, o modelo apenas precisa realizar uma correspondência lexical simples, sem raciocinar através de ambiguidades ou fazer qualquer processamento mais profundo. Mas na prática, os modelos precisam lidar com tarefas muito mais complexas.
Descobertas-chave sobre context rot
1. Modelos lutam com raciocínio em conversas longas
Considere um caso de uso comum: você está construindo um assistente de chat com memória. Um usuário tem uma conversa de múltiplas sessões com seu assistente e, algumas sessões atrás, mencionou que mora em São Francisco.
Agora, na sessão atual, ele pergunta: "Quais são algumas boas atividades ao ar livre para um dia ensolarado?"
Idealmente, o assistente deveria lembrar que o usuário mora em São Francisco e sugerir recomendações específicas da cidade, sem que o usuário precise se repetir. Uma abordagem ingênua seria simplesmente inserir todo o histórico de chat no prompt. Mas as pesquisas demonstram que isso não funciona bem na prática e gera outputs não confiáveis.
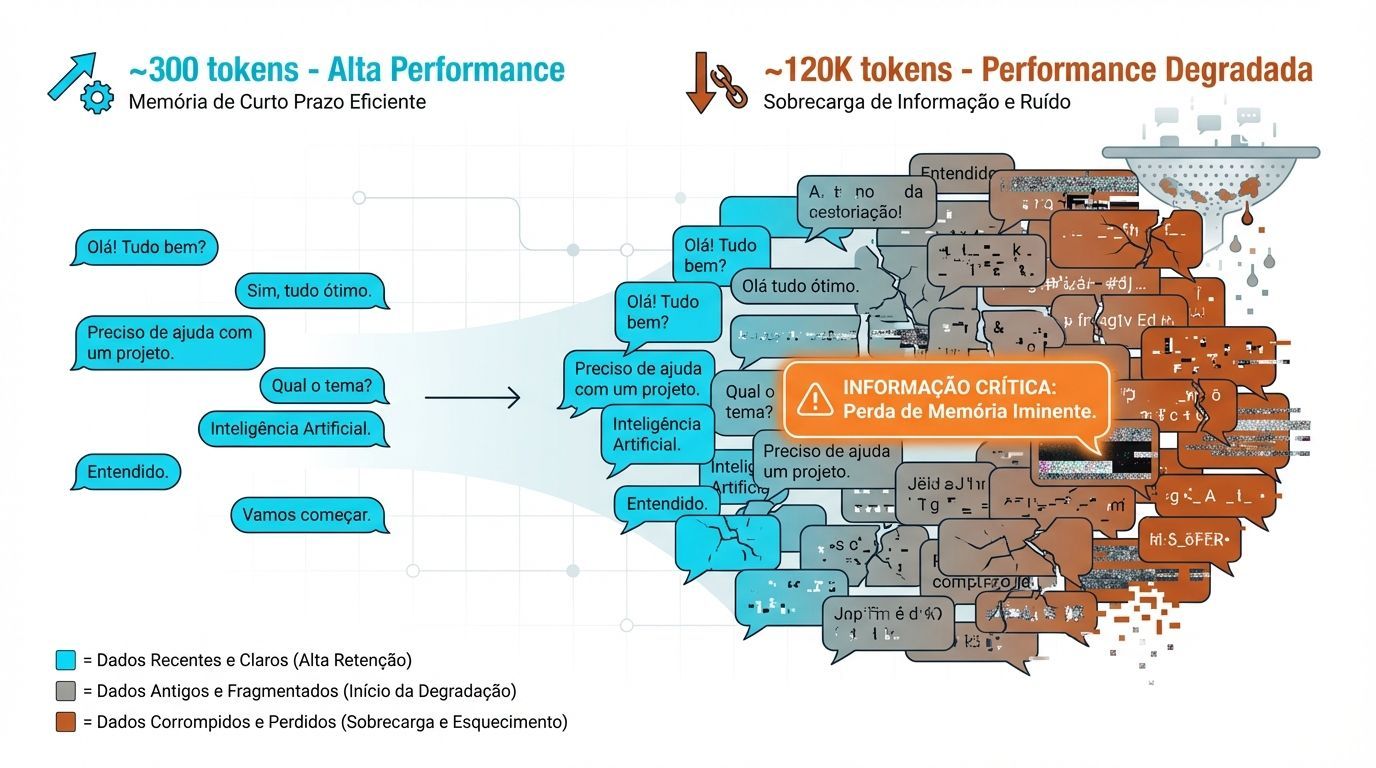
Para avaliar isso sistematicamente, a Chroma utilizou o benchmark LongMemEval, projetado para testar memória conversacional em contexto longo. Os resultados são reveladores:
Versão | Tokens médios | Performance do modelo |
|---|---|---|
Versão completa (500 mensagens) | ~120k tokens | Performance degradada |
Versão condensada (apenas trechos relevantes) | ~300 tokens | Performance significativamente melhor |
Mesmo os modelos mais avançados lutam para encontrar a informação certa quando muito ruído está presente.
2. Ambiguidade agrava o desafio de inputs longos
Considere um cenário real comum: você está pedindo a um modelo para corrigir um bug de código. Dificilmente você dirá exatamente quais linhas observar. Em vez disso, provavelmente dará uma instrução mais ampla como "descubra o que está causando esse bug" junto com um grande pedaço de código ao redor.
Os testes modificados de "needle in a haystack" variando o nível de ambiguidade revelam padrões importantes:
Exemplo de alta similaridade (baixa ambiguidade):
Pergunta: "Qual foi o melhor conselho sobre corrida que recebi do meu colega de faculdade?"
Agulha: "O melhor conselho sobre escrita que recebi de um colega de faculdade foi escrever toda semana."
Exemplo de baixa similaridade (alta ambiguidade):
Pergunta: "Qual foi o melhor conselho sobre corrida que recebi do meu colega de faculdade?"
Agulha: "Uma coisa que as pessoas podem não saber sobre mim é que eu escrevo toda semana. É o hábito mais útil que desenvolvi e começou na faculdade quando um cara aleatório no meu curso de Inglês sugeriu isso."

Conclusão crítica: À medida que a ambiguidade aumenta, a performance do modelo se degrada mais rapidamente. Importante notar que com inputs curtos, os modelos têm sucesso mesmo com os pares agulha-pergunta mais ambíguos. Isso mostra que esses modelos são capazes de lidar com ambiguidade, mas sua performance se deteriora quando o comprimento da entrada aumenta.
3. Distratores amplificam o problema
Além da ambiguidade, a presença de informações distratoras — conteúdo que parece relevante mas não é — agrava ainda mais a degradação de performance. Em contextos longos, os modelos têm dificuldade crescente em distinguir entre informação verdadeiramente relevante e ruído plausível.
LLMs não são sistemas computacionais confiáveis para longas entradas
Uma conclusão importante dessa pesquisa é que large language models não devem ser tratados como sistemas computacionais totalmente confiáveis quando lidam com contextos muito longos. Mesmo que tecnicamente suportem milhões de tokens, a qualidade das respostas se degrada de maneira previsível.
Isso tem implicações diretas para arquiteturas de sistemas:
❌ Evitar simplesmente "jogar" todo o histórico ou documentação no contexto
✅ Implementar estratégias inteligentes de filtragem e condensação de informação
✅ Utilizar técnicas de context engineering para otimizar inputs
Context engineering: a solução prática
Context engineering refere-se ao conjunto de técnicas para otimizar como a informação é apresentada aos LLMs. Algumas estratégias eficazes incluem:
Recuperação seletiva de informação
Em vez de incluir todo o histórico de uma conversa, use sistemas de busca semântica para recuperar apenas os trechos mais relevantes para a consulta atual.
Sumarização hierárquica
Para documentos ou conversas muito longas, crie resumos em múltiplos níveis de granularidade e inclua apenas o necessário.
Chunking inteligente
Divida conteúdo longo em pedaços semanticamente coerentes e processe-os de forma independente quando possível.
Prompt engineering adaptativo
Ajuste seus prompts com base no comprimento do contexto, tornando-os mais explícitos e diretivos quando o input é longo.
FAQ: Perguntas frequentes sobre context rot
P: Todos os modelos sofrem igualmente de context rot?
R: Não. Modelos mais avançados geralmente lidam melhor com contextos longos, mas todos mostram algum grau de degradação. A extensão varia entre arquiteturas e treinamentos diferentes.
P: Janelas de contexto maiores são inúteis então?
R: Não exatamente. Elas são úteis, mas não são uma solução mágica. É essencial combiná-las com técnicas de context engineering para resultados confiáveis.
P: Como posso testar se meu sistema sofre de context rot?
R: Crie testes comparando a performance do seu modelo com inputs completos versus inputs condensados contendo apenas informação relevante. Se houver diferença significativa, você está vendo context rot em ação.
P: RAG resolve o problema de context rot?
R: RAG (Retrieval-Augmented Generation) ajuda significativamente ao recuperar apenas informação relevante, mas a qualidade da recuperação é crítica. RAG mal implementado pode ainda sofrer de context rot se recuperar muita informação irrelevante.
Conclusão: construa sistemas de IA mais inteligentes

O fenômeno do context rot é uma realidade que desenvolvedores de aplicações de IA precisam considerar seriamente. Não basta confiar cegamente nas capacidades anunciadas de janelas de contexto cada vez maiores.
A chave está em implementar arquiteturas inteligentes que:
Filtrem informação proativamente
Priorizem relevância sobre volume
Testem sistematicamente a performance com diferentes comprimentos de input
Utilizem técnicas de context engineering
Ao entender e mitigar o context rot, você pode construir aplicações de IA mais confiáveis e eficientes, mesmo trabalhando com modelos de última geração. O futuro não está apenas em janelas de contexto maiores, mas em como usamos essas janelas de forma inteligente.
Este conteúdo foi inspirado na pesquisa conduzida por Kelly Hong, pesquisadora da Chroma, sobre como o aumento de tokens de entrada impacta a performance de LLMs.