- Data Hackers Newsletter
- Posts
- Context Engineering: conheça a evolução do Prompt Engineering para AI Agents
Context Engineering: conheça a evolução do Prompt Engineering para AI Agents
Entenda o Context Engineering, cujo objetivo é otimizar todo o conjunto de informações disponíveis para o modelo durante o processamento
Data Hackers
21 de fevereiro de 2026
A maneira como construímos aplicações com inteligência artificial está mudando rapidamente. Se nos últimos anos o foco esteve em prompt engineering - a arte de escrever instruções eficazes para modelos de linguagem - agora uma nova disciplina emerge: context engineering. Essa evolução reflete uma transformação fundamental: estamos deixando de lado aplicações simples de pergunta e resposta para construir agentes de IA capazes de operar autonomamente em tarefas complexas e de longo prazo.

O que é Context Engineering?
Context engineering vai além da simples otimização de prompts. Enquanto o prompt engineering se concentra em como escrever instruções eficazes para um modelo de linguagem, o context engineering aborda um desafio mais amplo: como gerenciar e otimizar todo o conjunto de informações (tokens) disponíveis para o modelo durante sua execução.
Pense no contexto como a "memória de trabalho" do modelo. Assim como nós, humanos, temos uma capacidade limitada de manter informações em nossa memória de curto prazo, os modelos de linguagem também possuem um orçamento finito de atenção. Cada token adicionado ao contexto consome parte desse orçamento, e à medida que o contexto cresce, a capacidade do modelo de processar informações com precisão pode diminuir.
Por que Context Engineering é crucial para AI Agents?
A importância do context engineering se torna evidente quando analisamos o fenômeno conhecido como context rot (deterioração de contexto). Pesquisas demonstram que, conforme aumentamos o número de tokens no contexto, a capacidade do modelo de recuperar informações específicas diminui gradualmente. Isso não significa que modelos com contextos maiores sejam ruins - pelo contrário, eles são extremamente poderosos - mas que precisamos ser estratégicos sobre o que incluímos nesse espaço limitado.

Essa limitação tem origem na arquitetura transformer que fundamenta os LLMs modernos. Nessa arquitetura, cada token pode "prestar atenção" a todos os outros tokens do contexto, criando n² relações para n tokens. Conforme o contexto cresce, essa rede de relações se torna cada vez mais complexa, diluindo a capacidade de atenção do modelo.
Anatomia de um contexto eficaz
Para construir agentes realmente capazes, precisamos seguir um princípio fundamental: encontrar o menor conjunto possível de tokens de alto valor que maximize a probabilidade do resultado desejado. Na prática, isso significa otimizar cada componente do contexto:
System prompts: clareza acima de tudo
Os system prompts devem usar linguagem simples e direta, apresentando ideias na "altitude certa". Isso significa evitar dois extremos comuns:
Excesso de rigidez: hardcoding de lógica complexa e frágil que tenta prever cada cenário
Excesso de generalidade: instruções vagas que não fornecem sinais concretos ou assumem contexto compartilhado incorretamente
A zona ideal está no meio: específico o suficiente para guiar o comportamento, mas flexível o suficiente para fornecer heurísticas fortes que orientem a ação do modelo.
Recomendamos organizar os prompts em seções distintas (como <background_information>, <instructions>, ## Tool guidance, etc.) usando tags XML ou cabeçalhos Markdown. O importante é começar com um prompt mínimo e adicionar instruções e exemplos conforme identificamos falhas durante os testes.
Tools: eficiência é fundamental
As ferramentas (tools) permitem que agentes operem em seu ambiente e obtenham novo contexto conforme trabalham. Por definirem o contrato entre agentes e seu espaço de informação/ação, é crucial que as tools promovam eficiência tanto retornando informações compactas quanto incentivando comportamentos eficientes do agente.
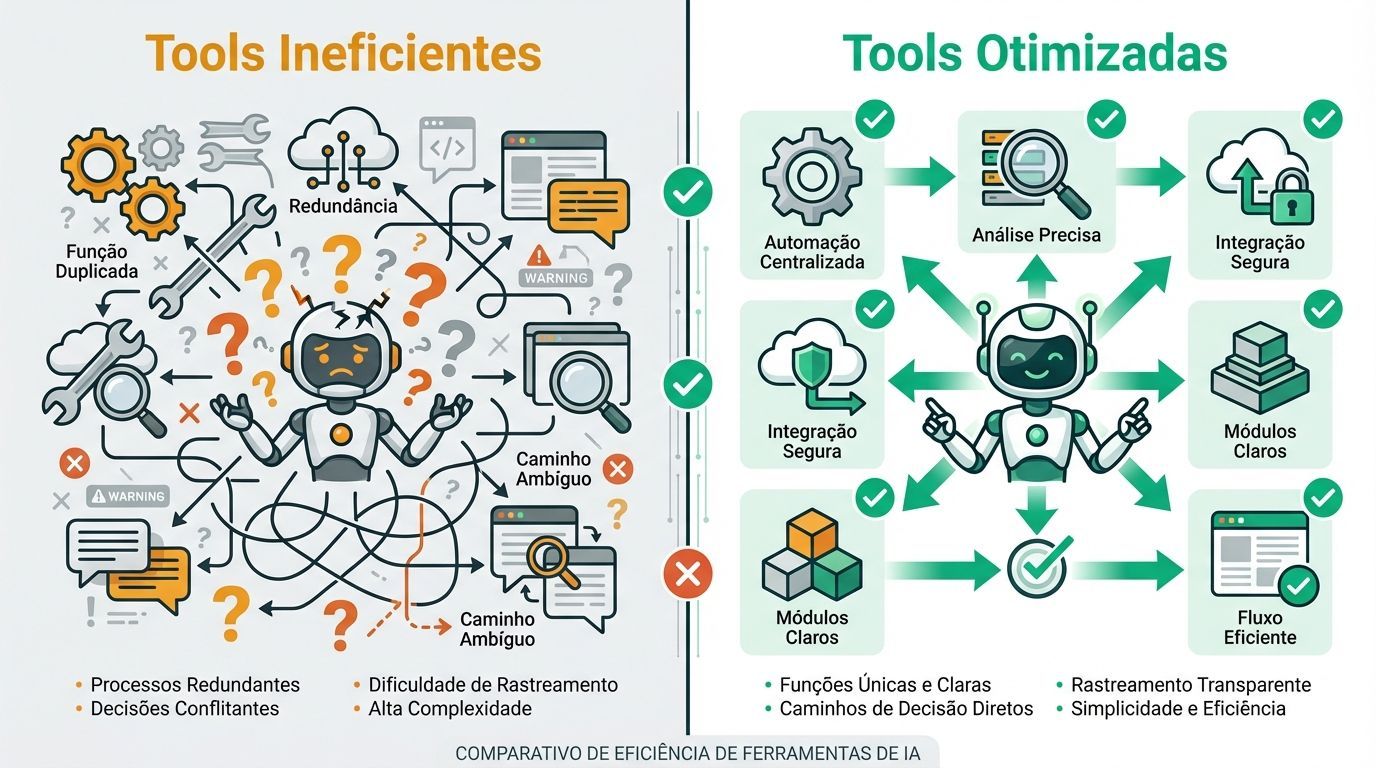
Um dos problemas mais comuns é ter conjuntos de ferramentas inchados que cobrem funcionalidades sobrepostas ou levam a pontos de decisão ambíguos. Se um engenheiro humano não consegue dizer definitivamente qual ferramenta usar em determinada situação, não podemos esperar que um agente de IA faça melhor.
As melhores práticas para tools incluem:
Funções autocontidas e robustas a erros
Descrições extremamente claras do propósito
Parâmetros de entrada descritivos e sem ambiguidade
Mínima sobreposição de funcionalidades
Few-shot prompting: exemplos valem mais que mil palavras
Fornecer exemplos continua sendo uma prática recomendada. No entanto, não recomendamos encher o prompt com uma lista exaustiva de casos extremos. Em vez disso, cure um conjunto de exemplos diversos e canônicos que retratem efetivamente o comportamento esperado do agente.
Recuperação de contexto e busca agêntica
À medida que o campo converge para agentes que usam ferramentas autonomamente em loops, estamos vendo uma mudança na forma como engenheiros pensam sobre contexto. Muitas aplicações ainda usam alguma forma de recuperação baseada em embeddings antes do tempo de inferência. Porém, cada vez mais equipes estão complementando esses sistemas com estratégias de contexto "just in time".
A abordagem "just in time"
Em vez de pré-processar todos os dados relevantes antecipadamente, agentes construídos com a abordagem "just in time" mantêm identificadores leves (caminhos de arquivos, queries armazenadas, links web, etc.) e usam essas referências para carregar dados dinamicamente no contexto em tempo de execução.

O Claude Code, por exemplo, usa essa abordagem para realizar análises complexas sobre grandes bancos de dados. O modelo pode escrever queries direcionadas, armazenar resultados e usar comandos Bash como head e tail para analisar grandes volumes de dados sem nunca carregar objetos de dados completos no contexto.
Essa abordagem espelha a cognição humana: geralmente não memorizamos corpus inteiros de informação, mas introduzimos sistemas externos de organização e indexação como sistemas de arquivos, caixas de entrada e favoritos para recuperar informações relevantes sob demanda.
Vantagens da exploração autônoma
Permitir que agentes naveguem e recuperem dados autonomamente também possibilita a revelação progressiva - ou seja, permite que agentes descubram incrementalmente contexto relevante através da exploração. Cada interação gera contexto que informa a próxima decisão:
Tamanhos de arquivo sugerem complexidade
Convenções de nomenclatura dão pistas sobre propósito
Timestamps podem ser um proxy para relevância
Os agentes podem montar entendimento camada por camada, mantendo apenas o necessário na memória de trabalho. Isso mantém o foco em subconjuntos relevantes em vez de se afogar em informações exaustivas mas potencialmente irrelevantes.
É claro que há um trade-off: exploração em tempo de execução é mais lenta que recuperar dados pré-computados. Além disso, engenharia opinada e cuidadosa é necessária para garantir que um LLM tenha as ferramentas e heurísticas certas para navegar efetivamente sua paisagem de informações.
Estratégias para tarefas de longo prazo
Tarefas de longo prazo exigem que agentes mantenham coerência, contexto e comportamento direcionado a objetivos ao longo de sequências de ações onde a contagem de tokens excede a janela de contexto do LLM. Para tarefas que abrangem dezenas de minutos a múltiplas horas de trabalho contínuo, como migrações de grandes bases de código ou projetos de pesquisa abrangentes, agentes requerem técnicas especializadas.

1. Compactação
Compactação é a prática de pegar uma conversa próxima do limite da janela de contexto, resumir seus conteúdos e reiniciar uma nova janela de contexto com o resumo. Geralmente serve como a primeira alavanca em context engineering para obter melhor coerência de longo prazo.
No Claude Code, implementamos isso passando o histórico de mensagens para o modelo resumir e comprimir os detalhes mais críticos. O modelo preserva decisões arquiteturais, bugs não resolvidos e detalhes de implementação enquanto descarta saídas de ferramentas redundantes ou mensagens. O agente pode então continuar com este contexto comprimido mais os cinco arquivos acessados mais recentemente.
Dica importante: A arte da compactação está na seleção do que manter versus o que descartar. Compactação excessivamente agressiva pode resultar na perda de contexto sutil mas crítico cuja importância só se torna aparente mais tarde.
2. Note-taking estruturado (memória agêntica)
Note-taking estruturado, ou memória agêntica, é uma técnica onde o agente regularmente escreve notas persistidas em memória fora da janela de contexto. Essas notas são recuperadas de volta para a janela de contexto em momentos posteriores.
Esta estratégia fornece memória persistente com overhead mínimo. Como o Claude Code criando uma lista de tarefas, ou seu agente customizado mantendo um arquivo NOTES.md, este padrão simples permite que o agente rastreie progresso através de tarefas complexas.

Um exemplo fascinante é o Claude jogando Pokémon, que demonstra como memória transforma capacidades de agentes. O agente mantém contagens precisas através de milhares de passos do jogo - rastreando objetivos como "nos últimos 1.234 passos estive treinando meu Pokémon na Rota 1, Pikachu ganhou 8 níveis em direção ao alvo de 10."
Após resets de contexto, o agente lê suas próprias notas e continua sequências de treinamento multi-hora ou explorações de masmorras. Esta coerência através de etapas de sumarização possibilita estratégias de horizonte longo que seriam impossíveis mantendo toda a informação apenas na janela de contexto do LLM.
3. Arquiteturas multi-agente
Arquiteturas de sub-agentes fornecem outra forma de contornar limitações de contexto. Em vez de um agente tentar manter estado através de um projeto inteiro, sub-agentes especializados podem lidar com tarefas focadas com janelas de contexto limpas.
O agente principal coordena com um plano de alto nível enquanto sub-agentes realizam trabalho técnico profundo ou usam ferramentas para encontrar informações relevantes. Cada sub-agente pode explorar extensivamente, usando dezenas de milhares de tokens ou mais, mas retorna apenas um resumo condensado e destilado de seu trabalho (geralmente 1.000-2.000 tokens).
Como escolher a abordagem certa
A escolha entre essas abordagens depende das características da tarefa:
Técnica | Melhor para | Vantagens |
|---|---|---|
Compactação | Tarefas que exigem fluxo conversacional extenso | Mantém continuidade conversacional |
Note-taking | Desenvolvimento iterativo com marcos claros | Persistência de longo prazo com overhead mínimo |
Multi-agente | Pesquisa e análise complexas | Exploração paralela e separação de preocupações |
O futuro do Context Engineering
Context engineering representa uma mudança fundamental em como construímos com LLMs. À medida que os modelos se tornam mais capazes, o desafio não é apenas criar o prompt perfeito - é curar cuidadosamente quais informações entram no orçamento de atenção limitado do modelo em cada etapa.
As técnicas que discutimos continuarão evoluindo conforme os modelos melhoram. Já estamos vendo que modelos mais inteligentes exigem menos engenharia prescritiva, permitindo que agentes operem com mais autonomia. Mas mesmo conforme as capacidades escalam, tratar contexto como um recurso precioso e finito permanecerá central para construir agentes confiáveis e eficazes.
Perguntas frequentes sobre Context Engineering
Q: Qual a diferença principal entre prompt engineering e context engineering?
A: Prompt engineering foca em escrever instruções eficazes, especialmente system prompts. Context engineering é mais abrangente, gerenciando todo o estado de contexto (instruções do sistema, tools, dados externos, histórico de mensagens, etc.) durante múltiplas rodadas de inferência.
Q: Por que não podemos simplesmente usar janelas de contexto maiores?
A: Mesmo com janelas de contexto maiores, enfrentamos o fenômeno de "context rot" - a capacidade do modelo de recuperar informações com precisão diminui conforme o contexto cresce. Context engineering será necessário independentemente do tamanho da janela de contexto.
Q: Quando devo usar a abordagem "just in time" vs. recuperação pré-computada?
A: Use "just in time" quando: 1) os dados são muito dinâmicos, 2) você precisa de exploração adaptativa, 3) o custo de latência é aceitável. Use pré-computada quando: 1) velocidade é crítica, 2) os dados são relativamente estáticos, 3) você pode indexar efetivamente com antecedência.
Q: Como saber se meu contexto está otimizado?
A: Sinais de contexto bem otimizado incluem: consistência de comportamento, baixa taxa de erros, recuperação eficiente de falhas, e latência aceitável. Se o agente perde o foco, confunde informações ou toma decisões inconsistentes, o contexto provavelmente precisa de otimização.
Próximos passos
O context engineering está se tornando uma habilidade essencial para desenvolvedores que trabalham com IA. À medida que construímos agentes cada vez mais sofisticados, a capacidade de gerenciar eficientemente o contexto separará soluções medianas de agentes verdadeiramente capazes.
O princípio orientador permanece simples mas poderoso: encontre o menor conjunto possível de tokens de alto sinal que maximize a probabilidade do seu resultado desejado. Com prática e experimentação, você desenvolverá a intuição para equilibrar completude com eficiência, autonomia com controle, e exploração com foco.
Os modelos continuarão melhorando, mas a disciplina fundamental de pensar em contexto - considerar holisticamente o estado disponível para o LLM em qualquer momento - permanecerá no centro da construção de agentes eficazes.