- Data Hackers Newsletter
- Posts
- Comparação entre os melhores vector databases open-source
Comparação entre os melhores vector databases open-source
Conheça as principais opções de vector databases do mercado e entenda qual se adequa melhor às suas necessidades
Data Hackers
20 de fevereiro de 2026

À medida que aplicações de inteligência artificial e machine learning se tornam cada vez mais sofisticadas, a necessidade de gerenciar e consultar embeddings de alta dimensão se torna crucial. Um vector database (banco de dados vetorial) é um sistema especializado para armazenar e consultar embeddings (vetores) de alta dimensão gerados por modelos como sentence transformers, CLIP ou LLMs.
Diferentemente de bancos de dados tradicionais que buscam correspondências exatas em strings, os vector databases realizam buscas por similaridade (usando métricas como cosseno, produto escalar ou distância euclidiana) para recuperar itens semanticamente similares em milissegundos, mesmo em escalas de bilhões de vetores.
O que os vector databases modernos oferecem
A maioria dos vector databases modernos fornecem capacidades essenciais para aplicações de IA:
Índices ANN (Approximate Nearest Neighbor): HNSW, IVF, PQ, entre outros
Busca híbrida: combina similaridade vetorial com filtros estruturados e metadados
Escalabilidade horizontal: distribuição entre máquinas e discos
Integrações com stacks de IA: SDKs Python, LangChain/LlamaIndex, conectores Kafka, etc.
Neste guia completo, vamos explorar os 10 principais vector databases open-source disponíveis atualmente, suas características, casos de uso e como escolher o mais adequado para seu projeto.

1. Milvus — potência cloud-native
Milvus é um dos vector databases open-source mais populares, construído desde o início para ser cloud-native e realizar buscas ANN em larga escala. Suporta índices IVF, HNSW e PQ, aceleração por GPU e foi projetado para implantações distribuídas, sendo adequado para centenas de milhões a bilhões de vetores.
Principais recursos
Escala massiva com sharding e nós de consulta distribuídos
Múltiplos tipos de índice (IVF, HNSW, PQ, ANNOY) para trade-offs entre velocidade e precisão
Filtragem escalar combinada com busca vetorial, time travel e particionamento
Amplo conjunto de SDKs (Python, Go, Java, Node, etc.) e integrações (Zilliz Cloud, Kafka, Spark)
Melhor para
RAG em larga escala com milhões a bilhões de documentos
Busca por similaridade de imagens, vídeos ou áudio com aceleração por GPU
Equipes confortáveis com Kubernetes e sistemas distribuídos
2. Qdrant — performance com Rust
Qdrant é um vector database de alto desempenho baseado em Rust, focado em busca híbrida, filtragem de payload e forte ergonomia para desenvolvedores. Oferece atualizações em tempo real, coleções e filtragem versátil, tornando-se favorito para busca semântica e sistemas de recomendação em produção.
GitHub: https://github.com/qdrant/qdrant
Principais recursos
ANN baseado em HNSW com alta recall e forte performance
Filtragem rica de payload (metadados) com condições aninhadas
Coleções, snapshots, replicação e escalonamento horizontal
API REST/gRPC, clientes oficiais (Python, Go, JS, Rust) e hospedagem Qdrant Cloud
Melhor para
Busca híbrida (metadados + semântica) e aplicações multi-tenant
Sistemas de recomendação, personalização e busca sobre conteúdo estruturado
Equipes que buscam equilíbrio entre performance, manutenibilidade e operações simples

3. Weaviate — vector database com knowledge graph
Weaviate é um vector database open-source que combina objetos com vetores, funcionando efetivamente como um "knowledge graph semântico" com APIs GraphQL e REST. Suporta vetorização automática via modelos integrados (OpenAI, Cohere, Hugging Face, etc.) ou aceita embeddings pré-computados.
Principais recursos
Objetos baseados em schema com propriedades e vetores
Vetorizadores integrados (OpenAI, Cohere, Transformers) e módulos (RAG, generative, rerankers)
APIs GraphQL/REST, multi-tenancy, replicação, RBAC
Opções cloud e self-hosted (Kubernetes, Docker)
Melhor para
Busca semântica com relacionamentos complexos de dados (knowledge graphs)
Equipes que desejam vetorização integrada e ferramentas RAG prontas para uso
Stacks pesadas em GraphQL que se beneficiam de design schema-first
4. Chroma — simples e focado em LLMs
Chroma é um embedding database open-source focado em aplicações LLM e RAG, com uma API muito simples e developer-first. É comumente usado como vector store local em frameworks LLM devido à facilidade de uso e implantação leve.
Principais recursos
API Python simples para coleções, documentos e embeddings
Provedores de embedding plugáveis e integração com LangChain e LlamaIndex
Persistência em disco ou em memória; adequado para datasets pequenos a médios
Foco na experiência do desenvolvedor sobre recursos distribuídos pesados
Melhor para
Prototipagem de pipelines RAG localmente ou em serviços pequenos
Agentes leves e ferramentas que precisam de armazenamento vetorial embutido
Desenvolvedores que valorizam uma API minimalista sobre recursos completos de DB

5. FAISS — biblioteca para performance bruta
FAISS (Facebook AI Similarity Search) não é um servidor de banco de dados, mas uma biblioteca C++/Python para busca por similaridade e clustering extremamente rápidos. Excelente em performance bruta, especialmente com GPU, mas requer que você construa ou integre sua própria camada de armazenamento, metadados e infraestrutura de serviço.
Principais recursos
Grande variedade de algoritmos ANN (IVF, HNSW, PQ, OPQ, etc.)
Índices acelerados por GPU para throughput massivo
Suporta embeddings em escala de bilhões em memória ou em disco com configurações personalizadas
Usado como motor subjacente em alguns vector databases e sistemas de busca personalizados
Melhor para
Equipes de ML/pesquisa que precisam de controle refinado sobre indexação e busca
Serviços vetoriais personalizados dentro de plataformas de dados existentes
Benchmarks e sistemas experimentais onde latência é crítica
6. PGvector — busca vetorial dentro do PostgreSQL
pgvector é uma extensão PostgreSQL que adiciona tipos de dados vetoriais e operadores de busca por similaridade diretamente no Postgres. Permite que equipes reutilizem infraestrutura, roles e backups existentes do Postgres enquanto adicionam capacidades vetoriais.
Principais recursos
Novo tipo
vectorcom operadores de similaridade (<->, etc.)Índices ANN (IVFFlat, HNSW) integrados ao planejador de consultas do Postgres
Consultas híbridas sem problemas: joins, filtros, transações, tudo em um DB
Suportado por muitos provedores de Postgres gerenciado
Melhor para
Cargas de trabalho vetoriais pequenas a médias onde Postgres já é a espinha dorsal
Equipes que preferem simplicidade operacional a um sistema vetorial separado
Casos de uso com fortes requisitos transacionais junto com busca vetorial

7. Redis (Redis-Search / Redis-VSS) — em memória, baixa latência
Redis, via Redis Stack / RediSearch, suporta busca por similaridade vetorial, permitindo consultas de latência extremamente baixa em memória com busca híbrida sobre campos. É adequado para aplicações em tempo real como recomendações e personalização onde tempos de resposta devem ser sub-milissegundos.
GitHub: https://github.com/redis/redis (Redis core) e https://github.com/RedisLabs/redisearch
Principais recursos
Índices vetoriais em memória com algoritmos ANN
Consultas híbridas combinando texto, intervalos numéricos, tags e vetores
Pub/Sub, streams, padrões de cache complementam casos de uso vetoriais
Pode persistir em disco e replicar para alta disponibilidade
Melhor para
Recomendação em tempo real, ranking de feeds e personalização
Busca semântica em edge ou camada de cache
Equipes que já executam Redis como componente principal
8. Vespa — plataforma de search e serving
Vespa é um motor open-source de larga escala que combina busca, serving e capacidades vetoriais, originalmente construído no Yahoo. Suporta busca vetorial, busca textual, expressões de ranking e computação de features complexas em tempo de consulta.
Principais recursos
Busca vetorial, textual e estruturada em uma plataforma
Modelos de ranking flexíveis e pipelines de features
Construído para serving em larga escala e alto QPS com forte ferramental operacional
Adequado para busca empresarial e sistemas de recomendação
Melhor para
Stacks de busca unificadas (keyword + semântica + metadados)
Grandes organizações que precisam de uma camada de serving completa, não apenas um DB
Ajuste de relevância complexo além da distância vetorial pura
9. Jina vectordb — pythônico e cloud-friendly
jina-ai/vectordb é um vector database pythônico construído em cima de Jina e DocArray, focando em ergonomia para desenvolvedores e implantação flexível (local, on-prem, cloud, serverless). Expõe CRUD completo, interfaces gRPC/HTTP/WebSocket e múltiplos backends ANN.
Principais recursos
API Python simples com DocArray como modelo de dados
CRUD completo, indexação em lote e busca com scores de relevância
Múltiplas implementações ANN (exata, HNSW e outras)
Implantações serverless-ready e serving escalável via Jina
Melhor para
Equipes Python-centric construindo microserviços e pipelines de IA
Aplicações já usando Jina/DocArray para busca multimodal
Implantações flexíveis entre local, on-prem e cloud
Outras menções honrosas
Vários outros projetos open-source são amplamente utilizados:
Annoy — biblioteca de índice ANN simples, baseada em arquivo, para busca por similaridade offline
HNSWlib — implementação HNSW de alto desempenho usada como building block
Vald — motor vetorial nativo do Kubernetes construído em torno de gRPC e HNSW
Elastic / OpenSearch vector search — capacidades vetoriais adicionadas em motores de busca full-text
Lista de recursos no GitHub
Awesome Vector Database: https://github.com/mileszim/awesome-vector-database
Como escolher o vector database ideal
Ao escolher um vector database para uma stack pesada em IA/vetores, as principais dimensões a considerar são:
Escala e performance
Quantos embeddings? QPS? Metas de latência?
Modelo operacional
Você quer SaaS gerenciado, self-hosted ou biblioteca embarcada?
Modelo de dados
Precisa de filtragem rica de metadados, relacionamentos de grafo ou vetores simples?
Fit no ecossistema
Integra bem com sua linguagem, framework, cloud e bancos de dados existentes?
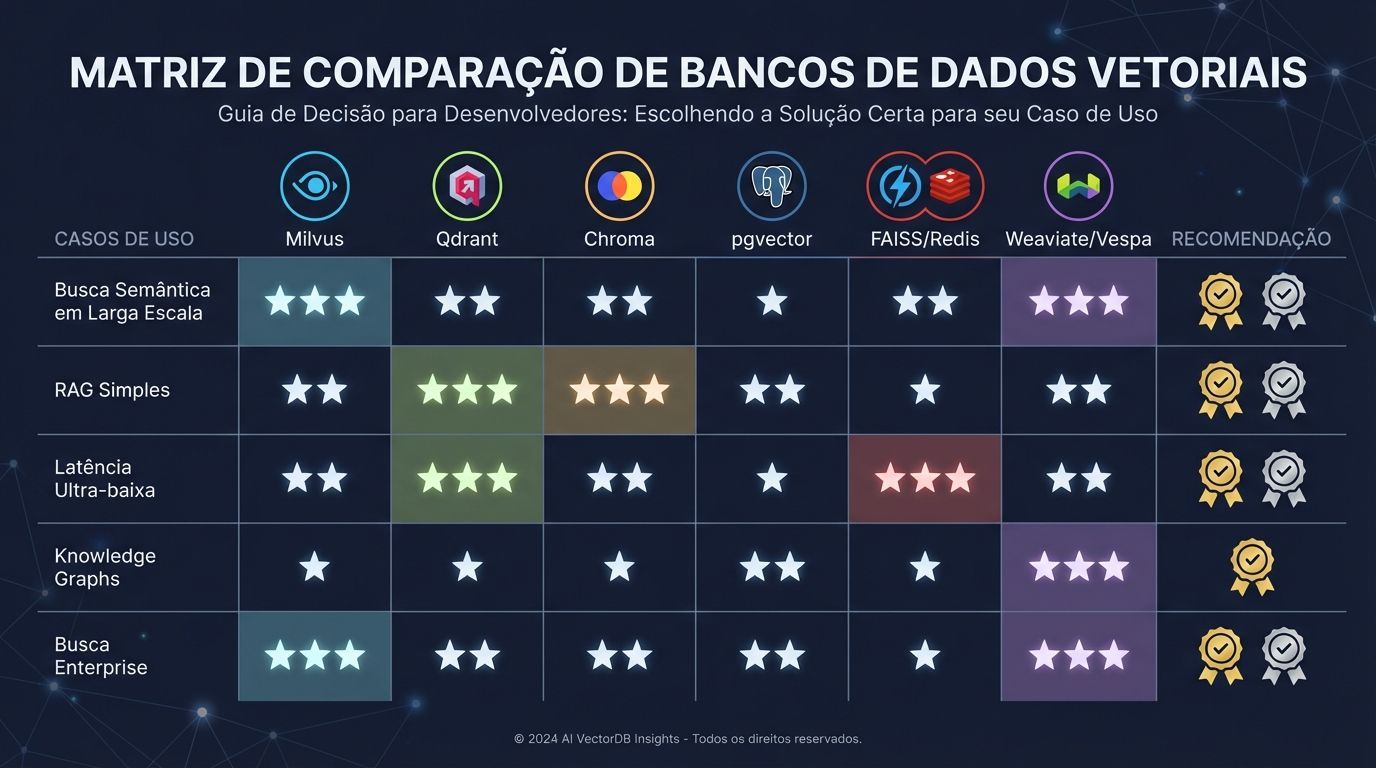
Recomendações práticas
Caso de uso | Vector database recomendado |
|---|---|
Busca semântica em larga escala em produção | Milvus ou Qdrant |
Configurações RAG simples e cargas de trabalho menores | Chroma ou pgvector |
Latência ultra-baixa ou máximo controle | FAISS ou Redis |
Knowledge graphs e relacionamentos complexos | Weaviate |
Busca unificada enterprise | Vespa |
Conclusão
Vector databases open-source se tornaram a espinha dorsal das aplicações modernas de IA, alimentando tudo desde busca semântica e pipelines RAG até sistemas de recomendação e knowledge graphs. Escolher o vector database correto depende de seus requisitos específicos — escala, performance, necessidades de integração e complexidade operacional.
Milvus e Qdrant são líderes para implantações em produção de larga escala, enquanto Chroma e pgvector oferecem simplicidade para prototipagem e cargas de trabalho menores. FAISS e Redis se destacam em cenários críticos de performance e tempo real, e Weaviate e Vespa fornecem recursos avançados para busca híbrida e necessidades empresariais.
Com opções como Jina vectordb e o ecossistema mais amplo, desenvolvedores agora podem construir sistemas de IA escaláveis, flexíveis e à prova de futuro sem vendor lock-in. A flexibilidade, transparência e suporte da comunidade dos vector databases open-source capacitam equipes a inovar mais rápido e se adaptar ao cenário em evolução da IA e machine learning.
A escolha do vector database correto pode ser o diferencial entre um projeto de IA bem-sucedido e um que enfrenta limitações de escalabilidade ou performance. Considere suas necessidades específicas, teste diferentes opções e escolha aquela que melhor se alinha com sua arquitetura e objetivos de longo prazo.