- Data Hackers Newsletter
- Posts
- Anthropic lança Claude Opus 4.6: novo modelo de IA que redefine o desenvolvimento de software
Anthropic lança Claude Opus 4.6: novo modelo de IA que redefine o desenvolvimento de software
Modelo supera modelos GPT e até versões anteriores do Claude
Data Hackers
5 de fevereiro de 2026
A Anthropic acaba de lançar o Claude Opus 4.6, e o mercado já está falando: este pode ser o salto mais significativo em modelos de linguagem desde o início de 2025. Com melhorias substanciais em coding, raciocínio agentic e capacidade de contexto expandida para 1M de tokens (em beta), o novo flagship da empresa promete transformar como desenvolvedores e profissionais do conhecimento trabalham com IA.
Em benchmarks de tarefas de trabalho real, o Opus 4.6 supera o GPT-5.2 da OpenAI em aproximadamente 144 pontos Elo no GDPval-AA — uma avaliação que mede performance em tarefas economicamente valiosas em finanças, jurídico e outros domínios profissionais.

Claude Opus 4.6: novo modelo da Anthropic promete revolucionar desenvolvimento de software
O que mudou no Claude Opus 4.6?
A principal evolução do modelo está na capacidade de planejar com mais cuidado, sustentar tarefas agentic por períodos mais longos e operar de forma mais confiável em codebases extensas. Mas vamos aos detalhes técnicos que realmente importam:
Melhorias em coding e debugging
O Opus 4.6 demonstra habilidades superiores de code review e debugging, conseguindo identificar e corrigir seus próprios erros com maior precisão. Em testes práticos, empresas como Cursor e GitHub relataram que o modelo consegue navegar em grandes codebases e identificar mudanças necessárias com precisão state-of-the-art.
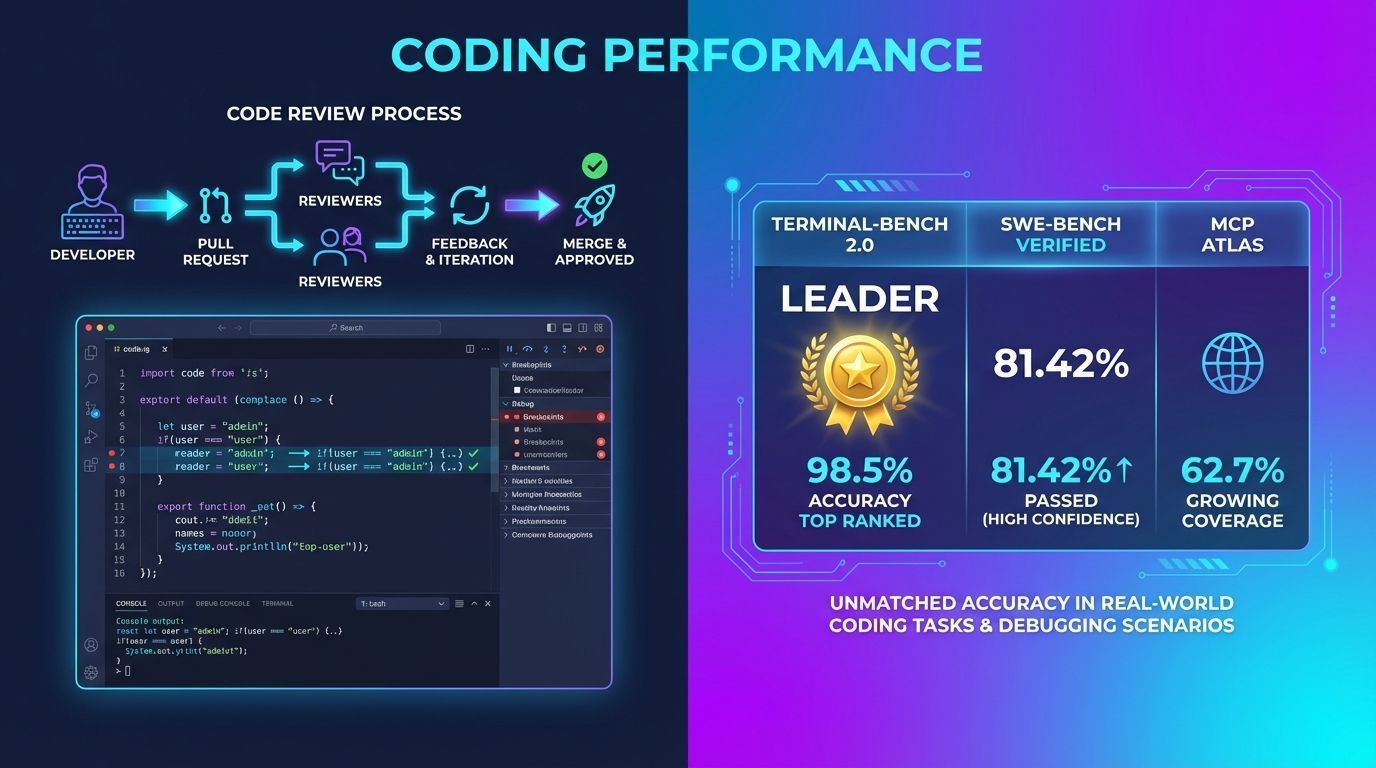
Claude 4.6: modelo é capaz de manter tarefas agenticas por mais tempo
Resultados em benchmarks de coding:
Benchmark | Claude Opus 4.6 | GPT-5.2 | Gemini 3 Pro |
|---|---|---|---|
Terminal-Bench 2.0 | 🥇 Líder | - | - |
SWE-bench Verified | 81.42% (com modificação de prompt) | - | - |
MCP Atlas | 62.7% (high effort) | - | - |
Contexto estendido: 1M tokens em beta
Pela primeira vez em um modelo classe Opus, a Anthropic disponibiliza uma janela de contexto de 1 milhão de tokens. Isso significa que desenvolvedores podem trabalhar com:
Codebases completas sem perder contexto
Documentação extensa de projetos
Análises financeiras complexas com múltiplos documentos
Pesquisas acadêmicas com dezenas de papers
E mais importante: o modelo mantém performance consistente mesmo em contextos longos. No benchmark MRCR v2 (8-needle 1M variant), o Opus 4.6 alcançou 76% de acurácia, enquanto o Sonnet 4.5 ficou em apenas 18.5%.

Claude 4.6: pela primeira vez, modelo possui janela de contexto de 1M de tokens
Adaptive thinking e agent teams: novos recursos para desenvolvedores
A Anthropic introduziu dois recursos que mudam significativamente como desenvolvedores podem usar o Claude:
Adaptive thinking
Anteriormente, desenvolvedores tinham apenas uma escolha binária entre habilitar ou desabilitar o extended thinking. Agora, com adaptive thinking, o Claude decide autonomamente quando raciocínio mais profundo seria útil.
Como funciona:
No nível de esforço padrão (high), o modelo usa extended thinking quando necessário
Desenvolvedores podem ajustar entre quatro níveis: low, medium, high e max
O modelo detecta pistas contextuais sobre quanto “pensar” antes de responder
Agent teams no Claude Code
Uma das inovações mais empolgantes é a capacidade de criar equipes de agentes que trabalham em paralelo. Ideal para tarefas que se dividem em trabalhos independentes, como code reviews extensos ou análise de múltiplos repositórios.
Casos de uso reais:
Yusuke Kaji, da Rakuten, relatou que o Opus 4.6 fechou 13 issues autonomamente e designou 12 issues para os membros certos da equipe em um único dia
A equipe gerenciava uma organização de ~50 pessoas através de 6 repositórios
O modelo tomou decisões de produto e organização enquanto sintetizava contexto de múltiplos domínios
Performance em tarefas de trabalho real: números impressionantes
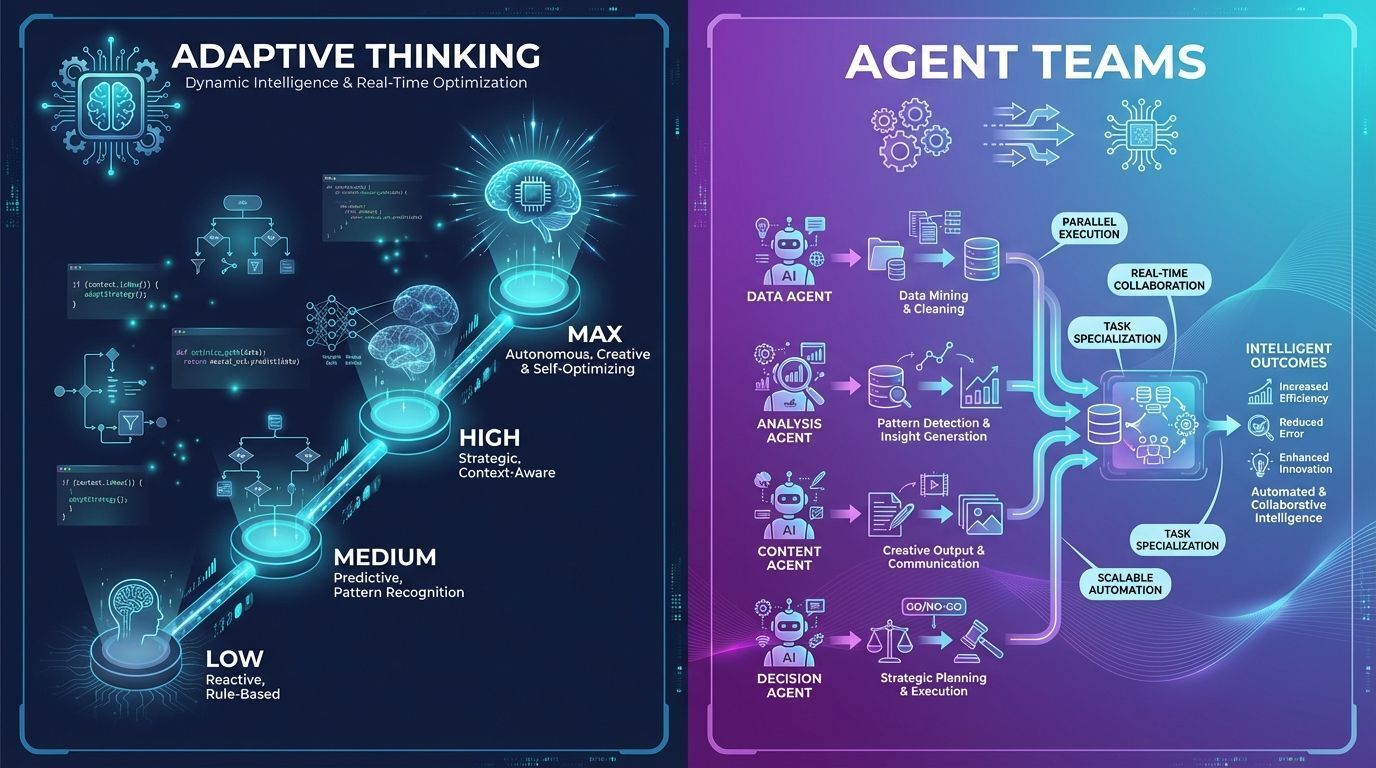
Claude 4.6: Adaptative Thinking e Agent Teams é grande novidade do modelo
O Opus 4.6 não é apenas teoricamente superior — ele entrega resultados mensuráveis em aplicações reais:
Busca e pesquisa agentic
O modelo conquistou a pontuação mais alta da indústria no BrowseComp, que mede a capacidade de localizar informações difíceis de encontrar online. Com harness multi-agente, a pontuação chegou a 86.8%.
Raciocínio expert-level
No Humanity’s Last Exam — um teste complexo e multidisciplinar de raciocínio — o Opus 4.6 lidera todos os outros modelos frontier. No ARC AGI 2, atingiu score competitivo com max effort.
Domínios específicos
Finanças e negócios:
No GDPval-AA, superou o GPT-5.2 em ~144 pontos Elo
Superou seu predecessor (Opus 4.5) em 190 pontos
Jurídico:
No BigLaw Bench, alcançou 90.2% de acurácia
40% de scores perfeitos
84% acima de 0.8
Cybersecurity:
Melhor performance no CyberGym para encontrar vulnerabilidades reais
Anthropic desenvolveu 6 novos probes de cybersecurity específicos
Integrações com ferramentas de produtividade
A Anthropic não se limitou a melhorar o modelo — expandiu significativamente as integrações com ferramentas de trabalho diário:
Claude in Excel: upgrades substanciais
Lida com tarefas de longa duração e mais difíceis
Planeja antes de agir
Ingere dados não estruturados e infere a estrutura correta sem orientação
Processa mudanças multi-etapas em uma única passagem
Claude in PowerPoint: agora em research preview
Lê layouts, fontes e slide masters para manter a identidade visual
Constrói apresentações a partir de templates ou descrições completas
Integra com dados processados no Excel
Preços e disponibilidade
O Claude Opus 4.6 está disponível hoje através de:
API da Anthropic
Todas as principais plataformas cloud (Amazon Bedrock, Google Cloud Vertex AI)
Pricing:
Pricing base: $5/$25 por milhão de tokens (input/output)
Prompts acima de 200k tokens: $10/$37.50 por milhão de tokens
Output de até 128k tokens
Inferência US-only disponível com pricing 1.1×
Para desenvolvedores, use claude-opus-4-6 via Claude API.
Para quem o Claude Opus 4.6 faz mais sentido?
Com base nos casos de uso e feedback do Early Access Program, o modelo é especialmente valioso para:
Desenvolvedores e engenheiros de software
Navegação em codebases grandes
Debugging complexo e análise de root cause
Migrações de código multi-milhão de linhas
Trabalho agentic com múltiplos repositórios
Profissionais de finanças
Análises financeiras complexas
Processamento de múltiplos documentos e relatórios
Tarefas que exigem raciocínio econômico sofisticado
Pesquisadores e acadêmicos
Análise de múltiplos papers
Síntese de conhecimento através de documentos extensos
Tarefas que exigem contexto de centenas de milhares de tokens
Equipes de produto e design
Prototipagem rápida de aplicações interativas
Geração de sistemas de design complexos
Iteração em ideias com feedback inteligente

Comparativo: Opus 4.6 vs. concorrentes
Característica | Claude Opus 4.6 | GPT-5.2 | Gemini 3 Pro |
|---|---|---|---|
Context window | 1M tokens (beta) | - | - |
Output máximo | 128k tokens | - | - |
Agent teams | ✅ Sim | ❌ Não | ❌ Não |
Context compaction | ✅ Sim (beta) | ❌ Não | ❌ Não |
Adaptive thinking | ✅ Sim | ❌ Não | ❌ Não |
Níveis de effort | 4 níveis | - | - |
Terminal-Bench 2.0 | 🥇 Líder | - | - |
GDPval-AA | +144 Elo vs GPT-5.2 | Baseline | - |
Limitações e considerações
Apesar dos avanços impressionantes, alguns pontos merecem atenção:
Overthinking em tarefas simples: O modelo pode “pensar demais” em problemas diretos, adicionando custo e latência. Solução: ajustar o parâmetro
/effortpara medium ou low.Pricing premium para contextos longos: Prompts acima de 200k tokens têm preço diferenciado ($10/$37.50 vs. $5/$25).
Features em beta: Context compaction e 1M token context ainda estão em beta, podendo ter comportamentos inesperados.
Curva de aprendizado: Recursos como agent teams e adaptive thinking requerem experimentação para uso ideal.
FAQ: perguntas frequentes sobre o Claude Opus 4.6
O Opus 4.6 substitui completamente o Sonnet para desenvolvimento?
Não necessariamente. O Sonnet continua sendo excelente para tarefas que não requerem o máximo de inteligência e é mais econômico. Use Opus 4.6 quando precisar de raciocínio profundo, contextos muito longos ou tarefas agentic complexas.
Como funcionam os níveis de effort?
São quatro níveis (low, medium, high, max) que controlam quanto o modelo “pensa” antes de responder. High é o padrão. Experimente diferentes níveis para encontrar o equilíbrio ideal entre qualidade, velocidade e custo.
Vale a pena pagar pelo contexto de 1M tokens?
Depende do caso de uso. Se você trabalha com codebases enormes, documentação extensa ou análises que requerem múltiplos documentos, sim. Para tarefas pontuais menores, o contexto padrão pode ser suficiente.
O modelo funciona bem em português?
Sim. Embora os benchmarks sejam majoritariamente em inglês, o Claude mantém boa performance em português brasileiro e suporta coding em múltiplas linguagens de programação.
Claude Opus 4.6 é um modelo mais caro, mas perfeito para tarefas complexas
Conclusão: Vale a pena usar o Claude 4.6?
O Claude Opus 4.6 representa mais do que uma melhoria incremental — é um salto qualitativo em como IA pode ser aplicada a trabalho real. A combinação de raciocínio aprimorado, contexto expandido, capacidades agentic e integração profunda com ferramentas de produtividade cria um novo patamar de possibilidades.
Para desenvolvedores, o modelo oferece uma experiência que se aproxima de ter um senior engineer trabalhando ao seu lado. Para profissionais do conhecimento, é uma ferramenta que finalmente consegue lidar com a complexidade de tarefas reais sem simplificações excessivas.
Os números em benchmarks são impressionantes, mas o feedback de empresas do Early Access Program talvez seja ainda mais revelador: este é um modelo que muda como equipes trabalham, não apenas como indivíduos usam IA.
Se você é desenvolvedor ou trabalha com dados e IA, vale a pena experimentar o Claude Opus 4.6 agora. A janela de contexto expandida sozinha já justifica testes em projetos com documentação extensa ou codebases grandes.
Para começar:
Acesse claude.ai para uso via interface
Consulte a documentação da API para integração
Explore o Claude Code para workflows de desenvolvimento