- Data Hackers Newsletter
- Posts
- Amazon S3 Files para AI agents: acesso nativo a arquivos sem migrar dados
Amazon S3 Files para AI agents: acesso nativo a arquivos sem migrar dados
Entenda o novo recurso que promete resolver problema de incompatibilidade e facilitar atuação de agentes de IA
Data Hackers
13 de abril de 2026
A arquitetura tradicional de agentes de IA enfrenta um problema fundamental: agentes operam em sistemas de arquivos usando ferramentas padrão para navegar diretórios e ler caminhos de arquivo. O desafio crítico é que a maioria dos dados empresariais está armazenada em sistemas de object storage, especialmente Amazon S3. Esses object stores servem dados através de chamadas de API, não por caminhos de arquivo — uma incompatibilidade que tem forçado times de engenharia a manter infraestruturas duplicadas.
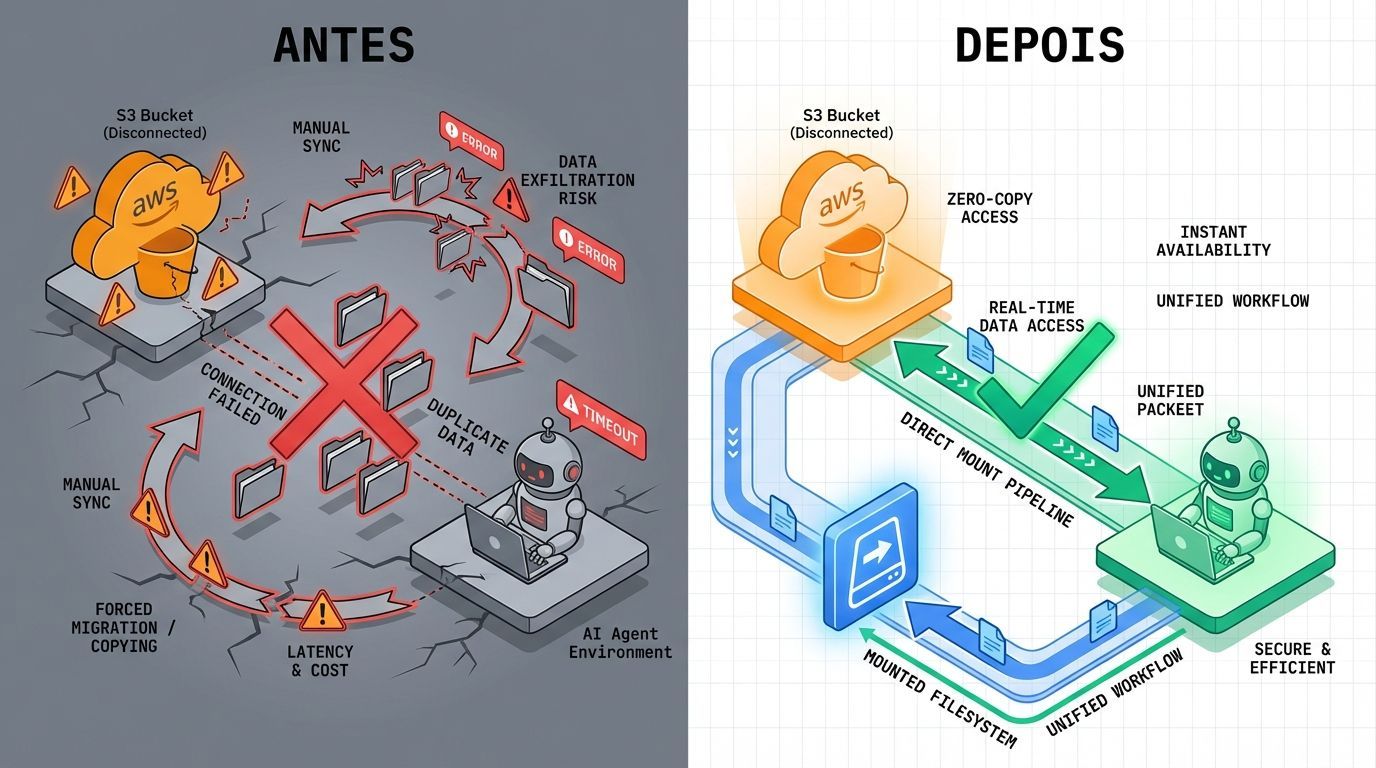
Com o avanço da IA agêntica, essa fricção se tornou insustentável. A resposta da Amazon é o S3 Files, uma solução que monta qualquer bucket S3 diretamente no ambiente local de um agente com um único comando — sem migração de dados necessária.
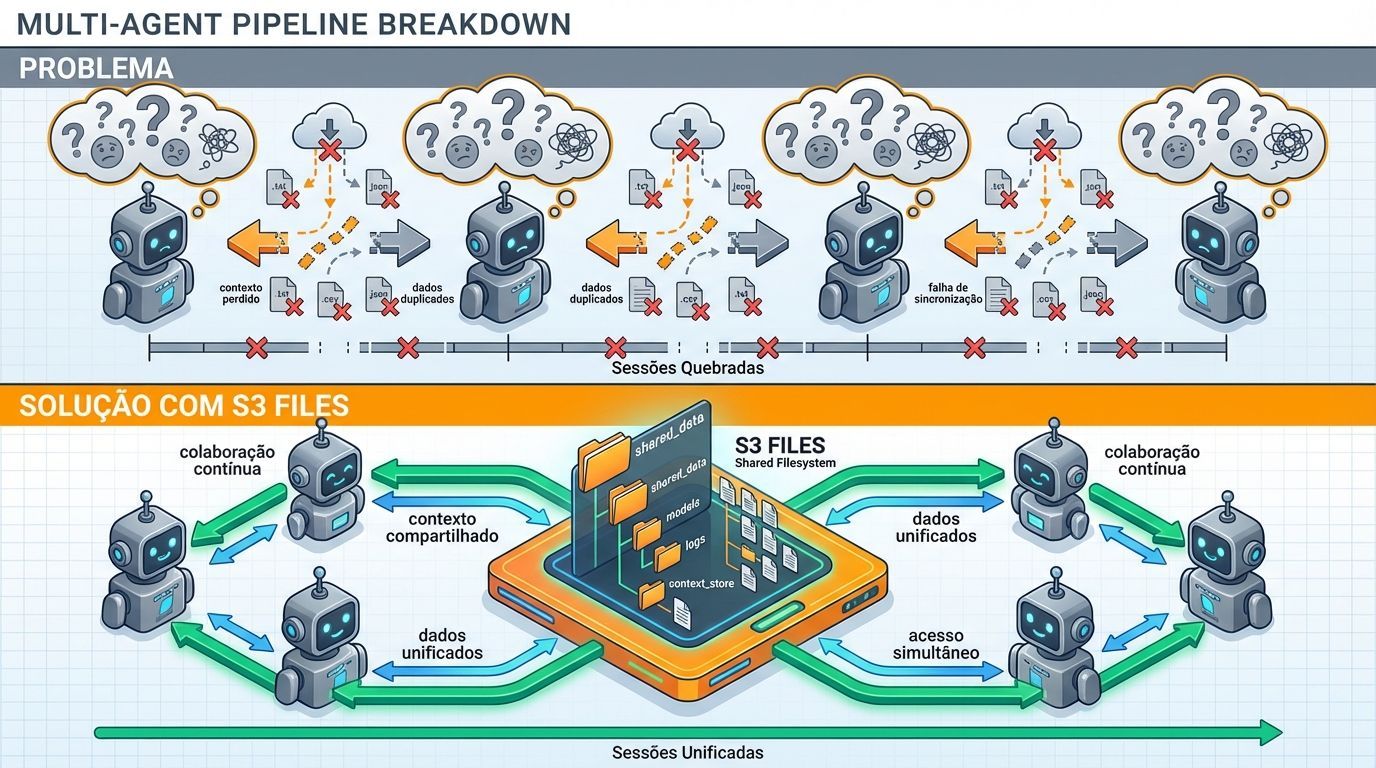
O problema oculto que quebra pipelines multi-agent
Antes do S3 Files, equipes da própria AWS enfrentavam constantemente a mesma limitação: agentes usando ferramentas como Kiro e Claude Code recorriam automaticamente a ferramentas de arquivo local, mas os dados estavam no S3. Fazer download local funcionava até o contexto do agente compactar e o estado da sessão ser perdido.
"Descobrimos que fazendo dados no S3 imediatamente disponíveis, como se fossem parte do sistema de arquivos local, tivemos uma aceleração enorme na capacidade de ferramentas como Kiro e Claude Code trabalharem com esses dados", explicou Andy Warfield, VP e distinguished engineer da AWS.
A incompatibilidade entre file storage e object storage não é apenas uma questão técnica — ela quebra workflows completos de agentes de IA:
Perda de contexto: Agentes precisam ser constantemente lembrados de que dados foram baixados localmente
Duplicação de dados: Manter file system separado ao lado do S3 cria redundância desnecessária
Sincronização complexa: Pipelines de sync para manter ambos os sistemas alinhados aumentam pontos de falha
Limitação de escala: Agentes não conseguem trabalhar eficientemente com datasets massivos armazenados em S3
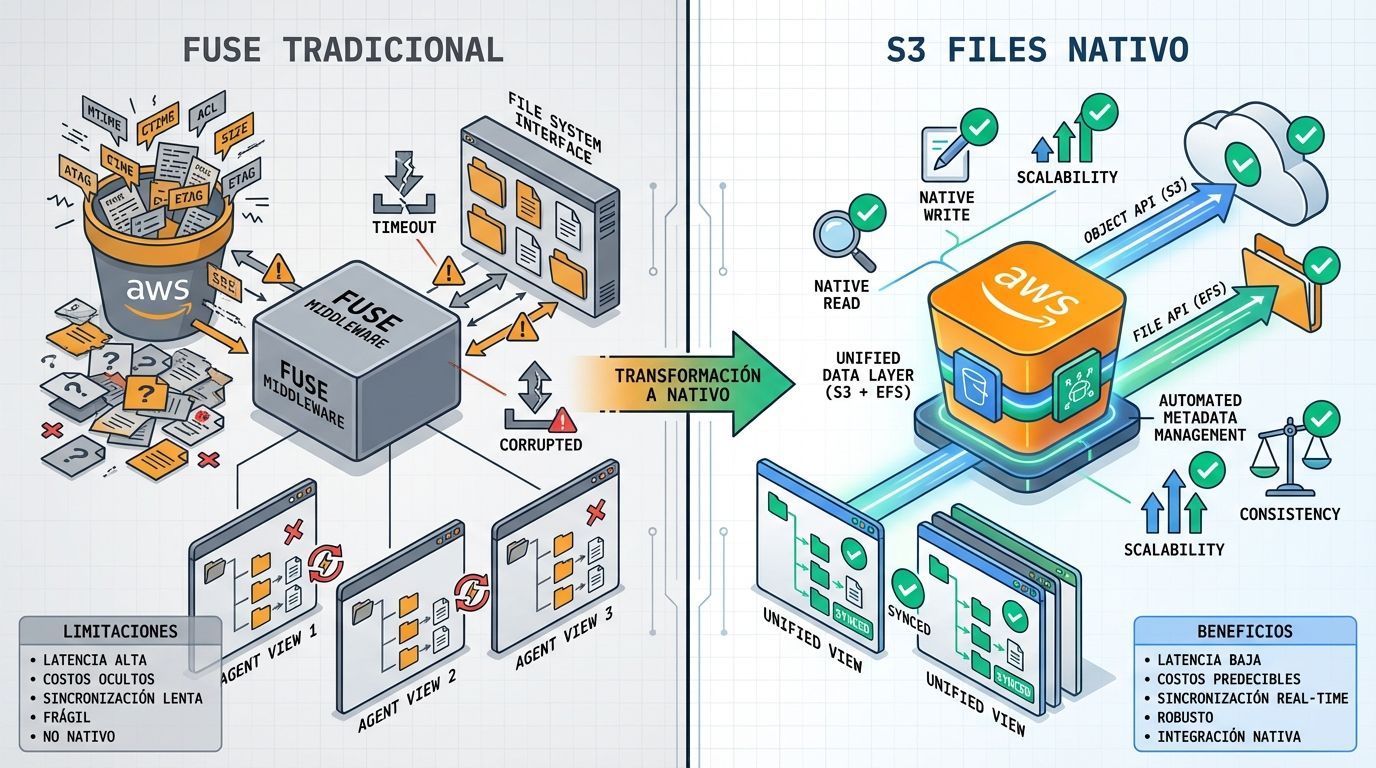
S3 Files vs FUSE: por que sua arquitetura pode estar ultrapassada
O S3 foi construído para durabilidade, escala e acesso baseado em API no nível de objeto. Essas propriedades o tornaram a camada de armazenamento padrão para dados empresariais, mas também criaram uma incompatibilidade fundamental com as ferramentas baseadas em arquivo que desenvolvedores e agentes dependem.
"S3 não é um file system e não possui semântica de arquivo em vários aspectos", afirmou Warfield. "Você não pode fazer um move, um movimento atômico de um objeto, e na verdade não existem diretórios no S3."
A limitação das soluções baseadas em FUSE
Tentativas anteriores de preencher essa lacuna dependiam de FUSE (Filesystems in USErspace), uma camada de software que permite montar um file system customizado em user space. Ferramentas como Mount Point da AWS, gcsfuse do Google e blobfuse2 da Microsoft usavam drivers baseados em FUSE para fazer seus respectivos object stores parecerem file systems.
O problema fundamental dessas soluções:
Abordagem FUSE | Limitação |
|---|---|
Metadados extras em buckets | Quebra a visualização da API de objeto |
Recusa de operações de arquivo | Object store subjacente não consegue suportar operações nativas |
Visões locais individuais | Cada agente mantém sua própria visão dos dados |
Sincronização problemática | Visões podem ficar dessincronizadas em ambientes multi-agent |
A arquitetura nativa do S3 Files
O S3 Files adota uma arquitetura completamente diferente. A AWS conecta sua tecnologia EFS (Elastic File System) diretamente ao S3, apresentando uma camada completa de file system nativo enquanto mantém o S3 como sistema de registro. Tanto a API de file system quanto a API de objeto S3 permanecem acessíveis simultaneamente contra os mesmos dados.
Como S3 Files acelera workflows de agentic AI
Warfield demonstrou a diferença prática com um caso de uso comum: análise de logs por agentes.
Antes do S3 Files:
Desenvolvedor instrui o agente onde os arquivos de log estão localizados
Agente precisa fazer download dos arquivos
Conforme o contexto compacta, o agente perde registro do que foi baixado
Desenvolvedor precisa lembrar constantemente ao agente sobre dados locais
Com S3 Files:
Desenvolvedor identifica que os logs estão em um path específico
Agente tem acesso imediato através do file system montado
Nenhum download necessário, contexto preservado
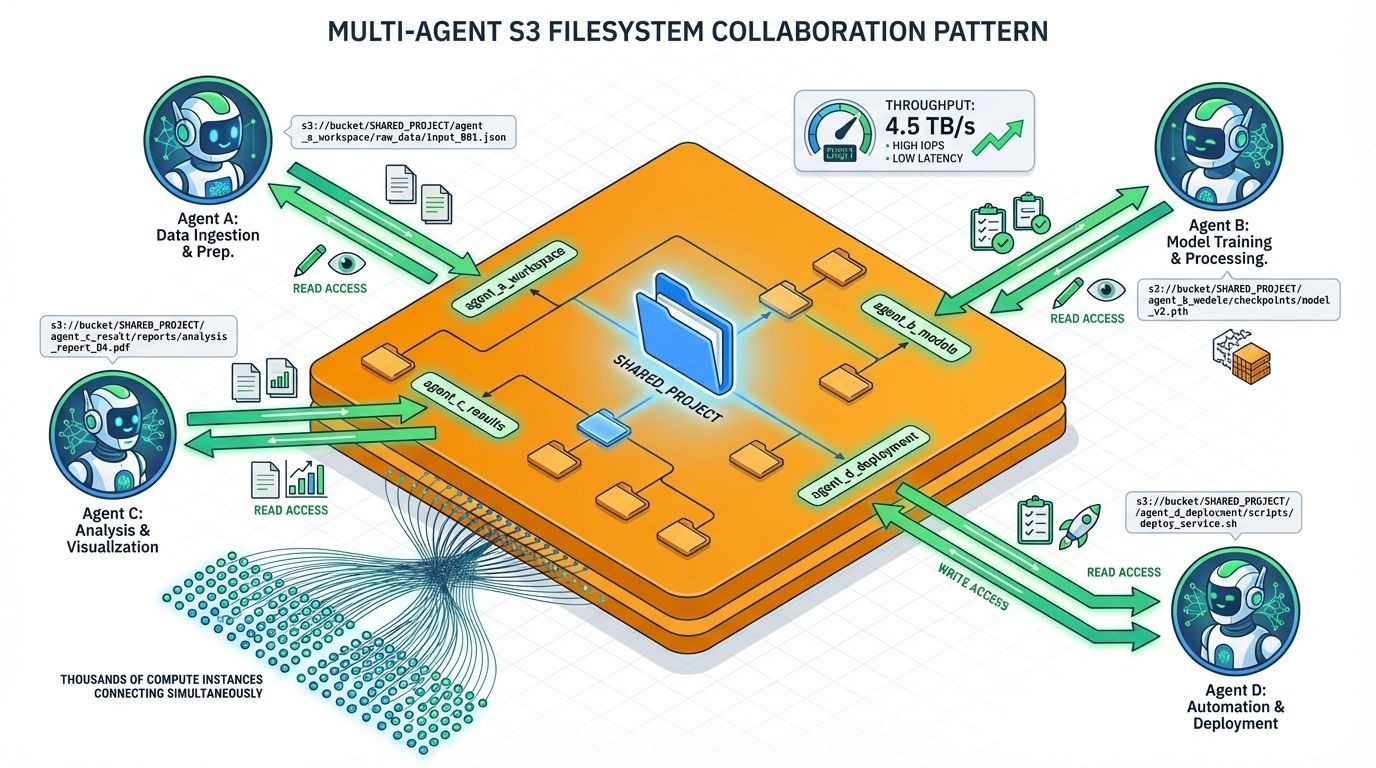
Pipelines multi-agent compartilhados
Para pipelines com múltiplos agentes, diversos agentes podem acessar o mesmo bucket montado simultaneamente. A AWS afirma que milhares de recursos de compute podem se conectar a um único file system S3 ao mesmo tempo, com throughput agregado de leitura alcançando múltiplos terabytes por segundo.
O estado compartilhado entre agentes funciona através de convenções padrão de file system:
Subdiretórios organizados por tarefa ou agente
Arquivos de notas para logging de investigações
Diretórios de projeto compartilhados que qualquer agente pode ler e escrever
Warfield descreveu times de engenharia da AWS usando esse padrão internamente, com agentes registrando notas de investigação e resumos de tarefas em diretórios de projeto compartilhados.
O que analistas dizem sobre S3 Files
Para Jeff Vogel, analista da Gartner, a distinção significativa do S3 Files não é primariamente performance, mas a eliminação da movimentação de dados.
"S3 Files elimina o data shuffle entre object storage e file storage, transformando S3 em um espaço de trabalho compartilhado e de baixa latência sem copiar dados", disse Vogel. "O file system se torna uma visualização, não outro dataset."
Vogel destaca que a solução elimina uma classe inteira de modos de falha, incluindo falhas inexplicáveis de treinamento/inferência causadas por metadata obsoleto — notoriamente difíceis de debugar. "Soluções baseadas em FUSE externalizam complexidade e problemas para o usuário."
Dave McCarthy, analista do IDC, vê implicações ainda mais amplas para IA agêntica:
"Para agentic AI, que pensa em termos de arquivos, paths e scripts locais, esse é o elo perdido. Permite que um agente de IA trate um bucket de escala exabyte como seu próprio disco rígido local, habilitando um nível de velocidade operacional autônoma que anteriormente era bloqueado pelo overhead de API associado a abordagens como FUSE."
S3 Files na prática: montando buckets com um único comando
A implementação prática do S3 Files é deliberadamente simples. Times de engenharia podem montar buckets S3 diretamente no ambiente de desenvolvimento ou produção de seus agentes sem reconfiguração de infraestrutura.
Cenários de uso imediato
Análise de dados por agentes:
Agentes acessam datasets massivos sem download prévio
Ferramentas padrão de linha de comando funcionam nativamente
Contexto preservado durante toda a sessão
Pipelines de RAG (Retrieval-Augmented Generation):
S3 Vectors se integra diretamente para similarity search
Agentes constroem índices sobre dados já armazenados
Sem necessidade de ETL ou duplicação
Colaboração multi-agent:
Múltiplos agentes trabalham sobre o mesmo dataset
Estado compartilhado através de diretórios comuns
Escalabilidade horizontal sem conflitos de sincronização
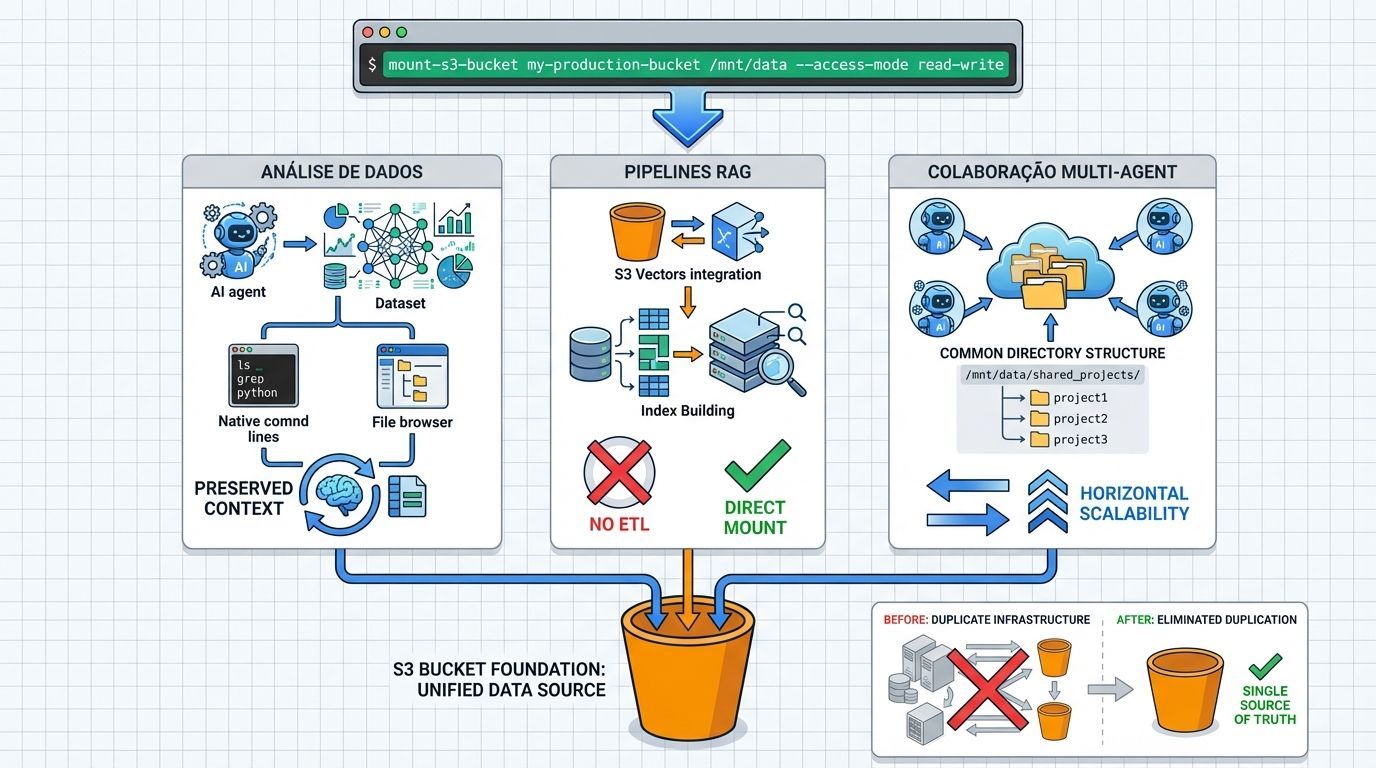
O fim da duplicação de dados entre file system e object storage
Para times empresariais que têm mantido um file system separado ao lado do S3 para suportar aplicações baseadas em arquivo ou workloads de agentes, essa arquitetura se torna desnecessária.
McCarthy do IDC posiciona o lançamento como um ponto de inflexão mais amplo: "O lançamento do S3 Files não é apenas S3 com uma nova interface; é a remoção do ponto final de fricção entre massive data lakes e IA autônoma. Ao convergir acesso a arquivo e objeto com S3, eles estão abrindo portas para mais casos de uso com menos retrabalho."
Para empresas consolidando infraestrutura de IA no S3, a mudança prática é concreta: S3 deixa de ser o destino para output de agentes e se torna o ambiente onde o trabalho do agente acontece.
FAQ: S3 Files para agentic AI
O que diferencia S3 Files de soluções FUSE tradicionais?
S3 Files conecta EFS diretamente ao S3, oferecendo semântica completa de file system enquanto mantém S3 como sistema de registro. Soluções FUSE criam uma camada de emulação que muitas vezes quebra compatibilidade.
Preciso migrar dados do S3 para usar S3 Files?
Não. S3 Files monta buckets existentes diretamente no ambiente do agente. Os dados permanecem no S3, sem necessidade de migração ou duplicação.
Quantos agentes podem acessar simultaneamente um bucket S3 Files?
A AWS afirma suporte para milhares de recursos de compute conectados simultaneamente a um único file system S3, com throughput agregado alcançando múltiplos terabytes por segundo.
S3 Files funciona com frameworks de IA existentes?
Sim. Como apresenta uma interface padrão de file system, funciona nativamente com ferramentas que agentes já usam, como Kiro, Claude Code e outros frameworks baseados em arquivo.
Qual a disponibilidade regional do S3 Files?
S3 Files está disponível agora na maioria das regiões AWS.
Impacto para times de engenharia de IA
"Todas essas mudanças de API que você está vendo dos times de storage vêm de trabalho em primeira mão e experiência de cliente usando agentes para trabalhar com dados", afirmou Warfield. "Estamos realmente focados singularmente em remover qualquer fricção e fazer essas interações funcionarem o melhor possível."
Para times construindo infraestrutura de IA agêntica, S3 Files representa a convergência entre onde os dados estão (object storage massivo e durável) e como agentes trabalham (file systems nativos com paths e diretórios). Essa convergência elimina não apenas overhead técnico, mas uma classe inteira de problemas de sincronização, perda de contexto e arquiteturas duplicadas que têm limitado a velocidade de desenvolvimento e deployment de sistemas agênticos em escala empresarial.