- Data Hackers Newsletter
- Posts
- 7 bibliotecas Python para feature engineering escalável que provavelmente você não conhece
7 bibliotecas Python para feature engineering escalável que provavelmente você não conhece
Conheça 7 bibliotecas que muito úteis para transformar dados brutos em variáveis explicativas significativas
Data Hackers
5 de fevereiro de 2026

Feature engineering é um dos pilares fundamentais em projetos de ciência de dados e machine learning. É através dele que transformamos dados brutos — muitas vezes bagunçados e sem estrutura clara — em variáveis explicativas significativas que alimentam nossos modelos. A complexidade desse processo pode variar drasticamente dependendo do volume de dados, sua estrutura e os objetivos do projeto.
Embora bibliotecas populares como Pandas e scikit-learn ofereçam funcionalidades básicas para manipulação de dados e feature engineering, existem ferramentas especializadas que vão muito além, especialmente quando falamos de datasets massivos e automação de transformações complexas. O problema? Muitos profissionais simplesmente não conhecem essas alternativas poderosas.
Neste artigo, vamos explorar 7 bibliotecas Python que podem revolucionar seus pipelines de feature engineering, mas que raramente aparecem nos tutoriais convencionais.
1. NVTabular: aceleração com GPU para dados tabulares

Desenvolvida pela NVIDIA-Merlin, a NVTabular é uma biblioteca especializada em preprocessamento e feature engineering para datasets tabulares, com um diferencial crucial: aceleração por GPU. Essa característica a torna especialmente valiosa para quem trabalha com grandes volumes de dados destinados ao treinamento de modelos de deep learning.
A biblioteca foi concebida pensando especificamente em sistemas de recomendação modernos baseados em redes neurais profundas (DNNs), onde a velocidade de processamento pode fazer uma diferença significativa entre um projeto viável e um inviável.
Principais vantagens:
Processamento massivamente paralelo usando GPUs
Otimizada para pipelines de recomendação em larga escala
Integração nativa com frameworks de deep learning
2. FeatureTools: automatização inteligente de features
A FeatureTools, desenvolvida pela Alteryx, revoluciona o conceito de feature engineering ao introduzir automação através do algoritmo de Deep Feature Synthesis (DFS). Em vez de criar features manualmente, a biblioteca analisa matematicamente as relações entre variáveis para gerar automaticamente features complexas e "profundas".

O grande diferencial é sua capacidade de trabalhar tanto com dados relacionais quanto com séries temporais, minimizando drasticamente a quantidade de código necessário para gerar features sofisticadas.
Veja um exemplo prático de como aplicar DFS com FeatureTools:
customers_df = pd.DataFrame({'customer_id': [101, 102]})
es = es.add_dataframe(
dataframe_name="customers",
dataframe=customers_df,
index="customer_id"
)
es = es.add_relationship(
parent_dataframe_name="customers",
parent_column_name="customer_id",
child_dataframe_name="transactions",
child_column_name="customer_id"
)
3. Dask: paralelização eficiente para grandes datasets
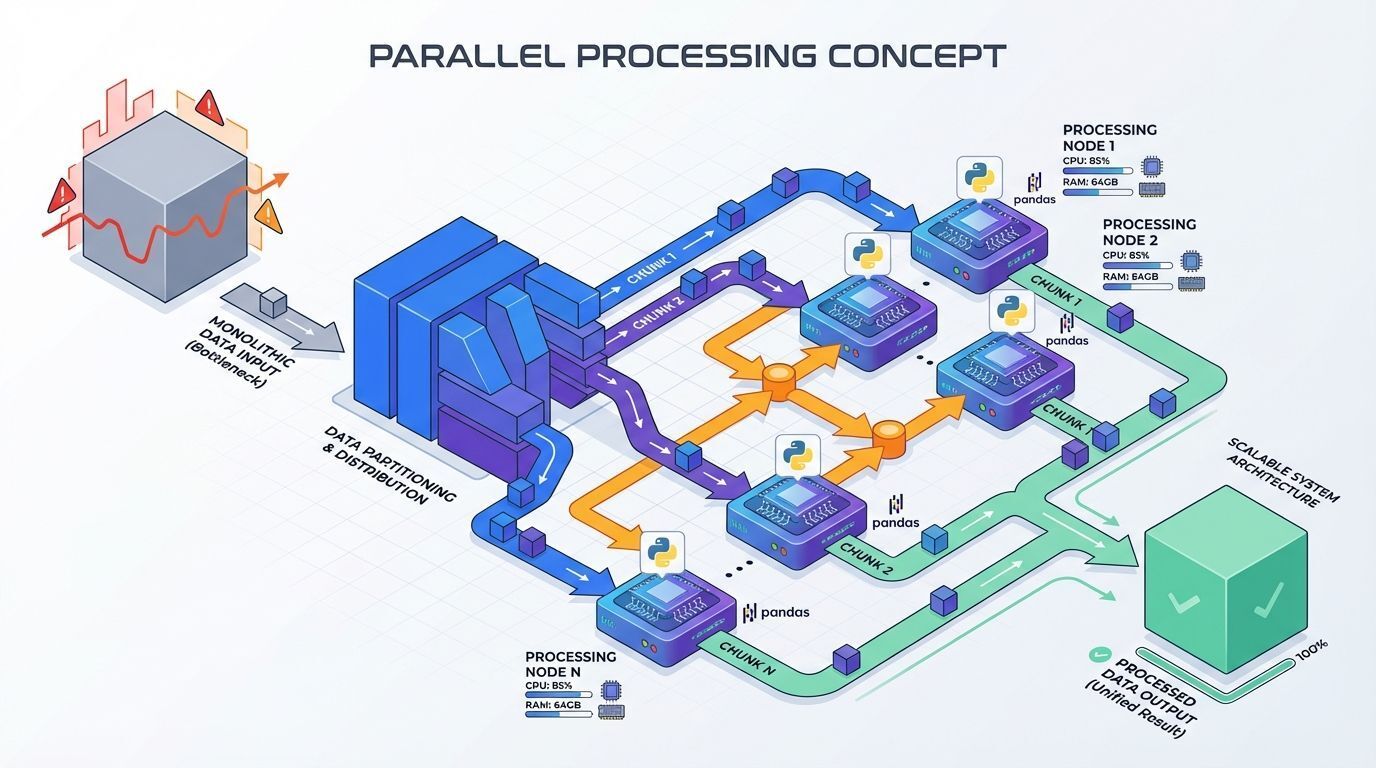
O Dask está conquistando cada vez mais espaço na comunidade Python como a solução definitiva para computações paralelas. Sua proposta é simples mas poderosa: escalar transformações tradicionais do Pandas e scikit-learn através de computações distribuídas em clusters.
A biblioteca permite que você processe datasets que não cabem na memória RAM, dividindo o trabalho em tarefas menores executadas em paralelo. Isso torna pipelines de feature engineering muito mais rápidos e economicamente viáveis.
Por que usar Dask:
Sintaxe familiar para usuários de Pandas
Escalabilidade horizontal através de clusters
Processamento de dados que excedem a memória disponível
Integração com ecossistema científico Python
4. Polars: performance extrema com Rust
Rivalizando com Dask em popularidade crescente, e aspirando ao trono do Pandas, temos o Polars: uma biblioteca de dataframes baseada em Rust que utiliza lazy evaluation e API de expressões para otimizar operações em grandes datasets.

Muitos consideram Polars como a versão de alta performance do Pandas. Se você já domina Pandas, a curva de aprendizado é mínima, mas os ganhos de performance podem ser extraordinários.
Diferenciais do Polars:
Performance superior através de implementação em Rust
Lazy evaluation para otimização automática de queries
API expressiva e intuitiva
Processamento eficiente de memória
Para quem deseja se aprofundar, existem diversos one-liners em Polars que podem acelerar significativamente workflows de dados, incluindo tarefas de feature engineering.
5. Feast: feature store para produção
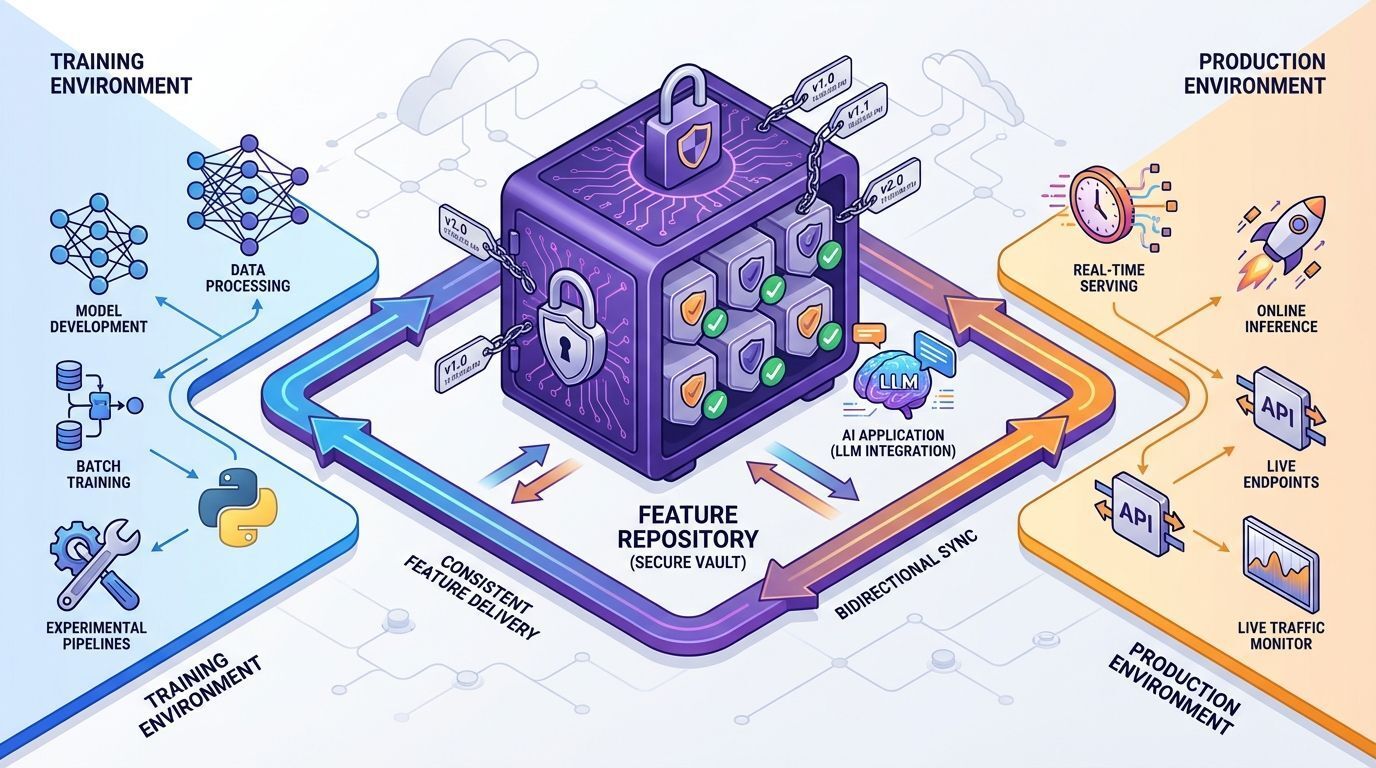
O Feast representa uma abordagem diferente: em vez de focar na criação de features, ele atua como um feature store open-source, garantindo que features estruturadas sejam entregues de forma consistente para aplicações de IA em produção.
Sua importância é crítica especialmente em aplicações baseadas em Large Language Models (LLMs), onde a consistência entre treinamento e inferência pode fazer ou quebrar um projeto.
Casos de uso principais:
Garantir consistência entre treino e produção
Servir features para modelos em tempo real
Integração com frameworks como denormalized
Governança e versionamento de features
6. tsfresh: extração avançada de features em séries temporais
Quando o assunto é séries temporais em larga escala, a tsfresh se destaca como ferramenta especializada em extração automatizada de features. A biblioteca é capaz de computar centenas de características significativas — desde propriedades estatísticas até espectrais — a partir de dados temporais.

Um recurso particularmente útil é o filtro de relevância, que automaticamente identifica e retém apenas features que realmente contribuem para o modelo de machine learning.
Exemplo de extração de features com janelas deslizantes:
features_rolled = extract_features(
rolled_df,
column_id='id',
column_sort='time',
default_fc_parameters=settings,
n_jobs=0
)
Recursos principais:
Extração automática de centenas de features temporais
Filtro de relevância integrado
Suporte para processamento paralelo
Configurações customizáveis de features
7. River: machine learning online e streaming
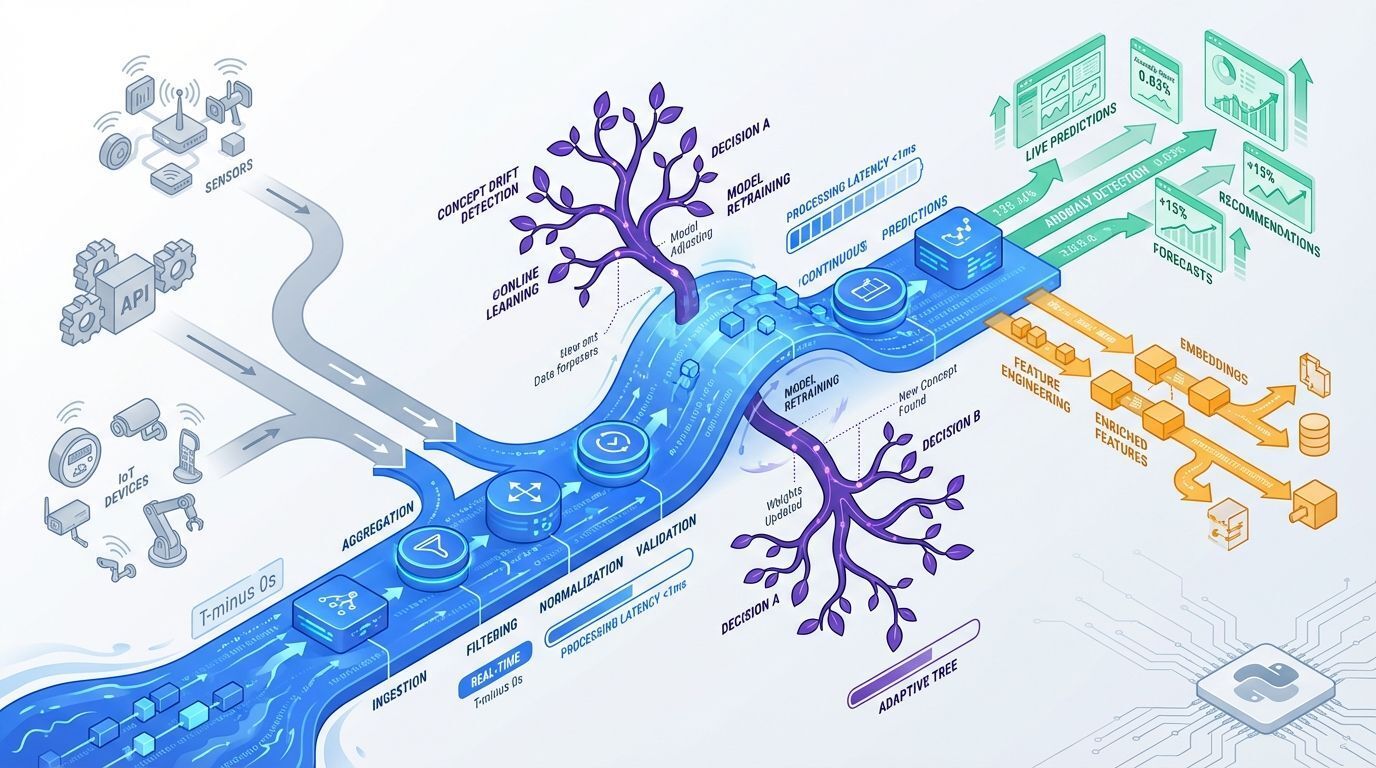
Fechando nossa lista, a biblioteca River foi projetada especificamente para workflows de machine learning online. Sua capacidade de realizar transformação e aprendizado de features em tempo real a torna ideal para cenários onde dados chegam continuamente.
O diferencial está em sua robustez para lidar com desafios raramente abordados em sistemas batch tradicionais, como concept drift e features que aparecem ou desaparecem ao longo do tempo.
Vantagens do River:
Processamento de streaming de dados
Adaptação automática a concept drift
Transformações de features em tempo real
Memória eficiente para dados ilimitados
FAQ: perguntas frequentes sobre feature engineering escalável
Qual biblioteca devo escolher para começar?
Depende do seu caso de uso. Para datasets grandes mas que cabem em memória, Polars é excelente. Para datasets massivos, Dask é mais apropriado. Para automação, comece com FeatureTools.
Essas bibliotecas substituem completamente Pandas?
Não necessariamente. Pandas continua sendo ideal para análises exploratórias e datasets menores. Essas bibliotecas complementam o ecossistema quando escalabilidade se torna crítica.
Como lidar com features em produção?
Feast é a escolha natural para gerenciar features em ambiente produtivo, garantindo consistência e governança adequada.
Considerações finais
Feature engineering é uma das etapas mais críticas em qualquer pipeline de machine learning, e as ferramentas certas podem fazer toda a diferença entre um projeto que escala e um que trava.
As 7 bibliotecas apresentadas neste artigo oferecem abordagens distintas para tornar feature engineering mais eficiente, escalável e automatizado. Algumas focam diretamente em criação de features, enquanto outras oferecem suporte complementar em cenários específicos.
Principais takeaways:
NVTabular para aceleração com GPU
FeatureTools para automação inteligente
Dask e Polars para processamento paralelo e eficiente
Feast para gerenciamento de features em produção
tsfresh para séries temporais
River para cenários de streaming
O próximo passo é experimentar essas ferramentas em seus próprios projetos. Comece pequeno, teste com subsets de dados e meça o impacto em performance antes de adotar em produção.
Qual dessas bibliotecas você está mais ansioso para testar? Compartilhe sua experiência nos comentários!